











GIAI

GIAI Research
GIAI Research Stories
더 이코노미 코리아


All News
Tech
Policy
Financial
Case Studies
Deep Tech
Deep Policy
Deep Financial
AI/DS Papers
AI/DS 이야기
GIAI Books
해외 AI/DS 소식
Fiscal Games in Overlapping Jurisdictions
Fiscal Games in Overlapping Jurisdictions
Published
Jay Hyoung-Keun Kwon*
* Swiss Institute of Artificial Intelligence, Chaltenbodenstrasse 26, 8834 Schindellegi, Schwyz, Switzerland
I. Introduction
Recent developments in the urban landscape—such as sub-urbanization, counter-urbanization, and re-urbanization—have given rise to complicated scenarios where administrative jurisdictions are newly formed and intersect with existing ones. This presents unique challenges to traditional models of tax competition. This paper examines the economic implications of such overlapping jurisdictions, particularly focusing on their impact on tax policy.
Overlapping jurisdictions are characterized by multiple local governments exercising different levels of authority over the same geographic area. These arrangements often merge as responses to address urban sprawl or provide specialized services tailored to local needs. However, they also create a intricate network of fiscal relationships that can lead to inefficiencies in resource allocation and public service delivery.
For instance, local governments in the U.S., including counties, cities, towns, and special districts, have varying degrees of taxing powers. Residents in certain areas might be subject to property taxes levied by their town, county, school district, and special districts (such as fire or library districts), all operating within the same geographic space. This multi-layered governance structure not only affects residents' tax burdens but also influences local governments' decision-making processes regarding tax rates and public service provision. The resulting fiscal landscape provides a rich setting for examining the dynamics of tax competition and cooperation among overlapping jurisdictions.
Traditional models of tax competition, such as Wilson [4] and Zodrow and Mieszkowski [5], typically assume clear demarcations between competing jurisdictions. However, these models do not adequately capture the dynamics of overlapping administrative divisions. In such settings, local governments must navigate not only horizontal competition with neighboring jurisdictions but also a form of vertical competition within the same geographic space.
This paper aims to extend the literature on tax competition by developing a theoretical framework that accounts for the unique characteristics of overlapping jurisdictions. Specifically, we address the following research questions:
- How do overlapping administrative divisions affect the strategic tax-setting behavior of local governments?
- What are the implications of such overlapping structures for the provision of public goods and services?
- How does the presence of overlapping jurisdictions influence the welfare outcomes predicted by traditional tax competition models?
To address these questions, we develop a game-theoretic model that incorporates multiple layers of local government operating within the same geographic space. This approach allows us to analyze the strategic interactions between overlapping jurisdictions and derive insights into the resulting equilibrium tax rates and levels of public good provision.
Our analysis contributes to the existing literature in several ways. First, it provides a formal framework for understanding tax competition in the context of overlapping jurisdictions, which is increasingly relevant in modern urban governance. Second, it offers insights into the potential inefficiencies that arise from such administrative structures and suggests possible policy interventions to mitigate these issues. Finally, it extends the theoretical foundations of fiscal federalism to account for more complex governance arrangements.
Our study addresses the current realities of fiscal federalism in developed economies as well as provides valuable insights for countries where local governments are yet to achieve significant fiscal autonomy. The lessons drawn from this analysis can inform policy discussions on decentralization, local governance structures, and intergovernmental fiscal relations in various contexts.
The remainder of this paper is organized as follows: Section II reviews the relevant literature on tax competition and fiscal federalism. Section III presents our theoretical model and derives key equilibrium results. Section IV discusses the implications of our findings for public policy and urban governance. Section V concludes and suggests directions for future research.
II. Literature Review
Tax competition has been one of the central themes in public economics. Tiebout [1]'s seminal work on local public goods laid the foundation for this field, proposing a model of "voting with feet" where residents moving to jurisdictions offering their preferred combination of taxes and public services. Oates [2] further developed these ideas and presented the decentralization theorem which posits that, under certain conditions, decentralized provision of public goods is welfare-maximizing.
Works of Wilson [4] and Zodrow and Mieszkowski [5] developed the basic tax competition model, where jurisdictions compete for a mobile capital tax base. This model predicts inefficiently low tax rates and underprovision of public goods, which is often referred to as the "race to the bottom." Wildasin [6] further demonstrated that the Nash equilibrium in tax rates is generally inefficient by incorporating strategic interactions between jurisdictions.
Researchers began to consider more diverse institutional settings. Keen and Kotsogiannis [11] analyzed the interaction between vertical tax competition (between different levels of government) and horizontal tax competition (between governments at the same level). Their work demonstrated that in federal systems, the tax rates can be high or low depending on the relative strength of vertical and horizontal tax externalities, contrary to the ``race to the bottom'' prediction of earlier models.
Itaya, Okamura, and Yamaguchi [12] examined tax coordination in a repeated game setting with asymmetric regions. They find that the sustainability of tax coordination depends on the degree of asymmetry between regions and the type of coordination--partial or full. While asymmetries can complicate coordination efforts, the repeated nature of interactions can facilitate cooperation under certain conditions. Their work demonstrates that full tax coordination can be sustained for a wider range of parameters compared to partial coordination.
Building on this, Ogawa and Wang [14] incorporated fiscal equalization into the framework of asymmetric tax competition in a repeated game context. Their findings reveal that fiscal equalization can influence the sustainability of tax coordination, sometimes making it more difficult to maintain. The impact of equalization schemes on tax coordination is contingent on the degree of regional asymmetry and the specific parameters of the equalization policy.
The case of overlapping jurisdictions represents a frontier in tax competition research. While not extensively studied, some works have begun to address such cases. Hochman, Pines, and Thisse [9] developed a model of metropolitan governance with overlapping jurisdictions, showing how this can lead to inefficiencies in public good provision. Esteller-Mor´e and Sol´e-Oll´e [10] analyzed tax mimicking in a setting with overlapping tax bases, finding evidence of both horizontal and vertical interactions.
Game-theoretic approaches have been instrumental in advancing our understanding of tax competition dynamics. Wildasin [6] pioneered the use of game theory in tax competition, modeling jurisdictions as strategic players in a non-cooperative game. This approach demonstrated that the Nash equilibrium in tax rates is generally inefficient, providing a formal basis for the ``race to the bottom'' hypothesis. The work of Itaya, Okamura, and Yamaguchi [12] and Ogawa and Wang [14] further extended this game-theoretic approach to repeated games, offering insights into the possibilities for tax coordination over time.
While these game-theoretic approaches have significantly advanced our understanding of tax competition, they have largely failed to address the complexities of fully overlapping jurisdictions. Most models assume clear boundaries between competing jurisdictions, leaving a gap in our understanding of scenarios where multiple levels of government have taxing authority over the same geographic area.
The welfare implications of tax competition have been a subject of ongoing debate. While the "race to the bottom" hypothesis suggests negative welfare consequences, some scholars have argued for potential benefits. Brennan and Buchanan [3] proposed that tax competition could serve as a check on the excessive growth of government, a view that has found some support in subsequent empirical work (e.g., [13]).
Policy responses to tax competition have also been extensively studied. Proposals range from tax harmonization [7] to the implementation of corrective subsidies [8]. The effectiveness of these measures, particularly in complex settings with overlapping jurisdictions, remains an active area of research.
While the literature on tax competition has made significant strides in understanding the dynamics of fiscal interactions between jurisdictions, several areas warrant further investigation. The case of fully overlapping jurisdictions, in particular, presents a rich opportunity for both theoretical modeling and empirical analysis. This study aims to fill in this gap by accounting for overlapping jurisdictions in traditional game-theoretic models of tax competition.
III. Model
This study extends the tax competition models of Itaya, Okamura, and Yamaguchi [12] and Ogawa and Wang [14] by introducing an overlapping jurisdiction. Our approach is grounded in the Solow growth model, which provides a robust framework for analyzing long-term economic growth and capital accumulation. The Solow model's emphasis on capital accumulation and technological progress makes it suitable for our analysis of tax competition, as these factors influence jurisdictions' tax bases and policy decisions.
The Solow model's assumptions of diminishing returns to capital and constant returns to scale align well with our focus on regional differences in capital endowments and production technologies. Moreover, its simplicity allows for tractable extensions to multi-jurisdiction settings.
A. Setup
We consider a country divided into three regions: two asymmetric regions, $S$ and $L$, and an overlapping region, $O$, which equally overlaps with $S$ and $L$. All regions have independent authority to impose capital taxes. This setup allows us to examine the interactions between horizontal tax competition (between $S$ and $L$) and the unique dynamics introduced by the overlapping jurisdiction $O$. Let us further denote that the regions of $S$ and $L$ that do not overlap with $O$ are $SS$(Sub-$S$) and $SL$(Sub-$L$), respectively, while those that overlap with $O$ are $OS$ and $OL$ (see Figure 1).
Here, we make the following key assumptions:
- Population: Population is evenly spread across the country. Hence, regions $S$ and $L$ have equal populations. Furthermore, regions $SS$, $SL$, and $O$ have equal populations. This assumption, while strong, allows us to isolate the effects of capital endowment and technology differences.
- Labor Supply and Individual Preferences: Residents inelastically supply one unit of labor to firms in their region and have identical preferences. Furthermore, they strive to maximize their utilities given their budget constraints. While this assumption simplifies labor market dynamics, it is reasonable in the short to medium term, especially in areas with limited inter-regional mobility.
- Production: Firms in each region produce homogeneous consumer goods and maximize their profits. This assumption allows us to focus on capital allocation without the complications of product differentiation.
- Capital Mobility: Capital is perfectly mobile across regions, reflecting the ease of capital movement in economies, especially within a single country.
- Asymmetric Endowments and Technology: Regions $S$ and $L$ differ in capital endowments and production technologies. This assumption captures real-world regional disparities and is crucial for generating meaningful tax competition dynamics.
- Public Goods Provision: Regions $S$ and $L$ provide generic public goods $G$, while region $O$ provides specific public goods $H$ to the extent that maximizes their representative resident's utilities. This reflects the often-observed division of responsibilities between different levels of government.
These assumptions, while simplifying the real world, allow us to focus on the core mechanisms of tax competition in overlapping jurisdictions. They provide a tractable framework for analyzing the strategic interactions between jurisdictions while capturing key elements of real-world complexity.
B. Production and Capital Allocation
Let $\bar{k}_i$ be the capital endowment per capita for regions $i$ and $\bar{k}$ be the capital endowments per capita of the national economy. For regions $S, L$ and $O$, it can be expressed as follows:
\begin{align}
\bar{k}_{s} \equiv \bar{k} - \varepsilon,\ \ \ \ \ \ \ \ \ \ \bar{k}_{L} \equiv \bar{k} + \varepsilon,\ \ \ \ \ \ \ \ \ \ \bar{k}_O = \bar{k} \equiv \frac{\bar{k}_{s} + \bar{k}_{L}}{2}
\end{align}
where $\varepsilon \in \left( 0,\ \bar{k} \right\rbrack$ represents asymmetric endowments between regions $S$ and $L$. $\bar{k}_O = \bar{k}$ follows from the assumption that the population is evenly dispersed across the country.
Let $L_i$ and $K_i$ be the labor and capital inputs for production in region $i$. It can be easily inferred that
\begin{align}
l\equiv L_S = L_L , \ \ \ \ \ \ \ \ \ \ \frac{2}{3}l \equiv L_{SS} = L_{SL} = L_{O}.
\end{align}
Furthermore, we denote
\begin{align}
K_{SS} \equiv \alpha_S K_S, \ \ \ \ \ \ \ \ \ \ K_{SL} \equiv \alpha_L K_L
\end{align}
for $0 < \alpha_S, \alpha_L < 1$.
With the key variables defined, the production function for each region $i$ is given by:
\begin{align}
F_i(L_i, K_i) = A_i L_i + B_i K_i - \frac{K_i^2}{L_i}
\end{align}
where $A_i$ and $B_i > 2K_i / L_i$ represent labor and capital productivity coefficients, respectively. Although regions $S$ and $L$ differ in capital production technology, there is no difference in labor production technology, so $A_{L} = A_{S}$ while $B_{L} \neq \ B_{S}$. Note that this function exhibits constant returns to scale and diminishing returns to capital. Furthermore, we assume that sub-regions without overlaps ($SL$ and $SS$) have equivalent technology coefficients with their super-regions ($L$ and $S$). The technology parameter of the overlapping region is a weighted average of $B_S$ and $B_L$, where the weights are the proportion of capital invested from $S$ and $L$.
As mentioned above, capital allocation across regions is determined by profit-maximizing firms and the free movement of capital. Let $\tau_i$ be the effective tax rate for region $i$. Then, we can infer that the real wage rate $w_i$ and real interest rates $r_i$ are:
\begin{equation}
\begin{aligned}
w_i &= A_i + \left(\frac{K_i}{L_i}\right)^2 \\
r_i &= B_i - 2K_i/L_i - \tau_i - t_i
\end{aligned}
\end{equation}
where $t_i = (1-\alpha_i)\tau_O$ for $i \in \{S, L\}$, $0$ for $i\in \{SS, SL\}$, $\tau_S$ for $i = OS$, and $\tau_L$ for $i = OL$.
The capital market equilibrium for the national economy is reached when the sum of capital demands is equal to the exogenously fixed total capital endowment: $K_S + K_L = 2l\bar{k}$. In equilibrium, the interest rates and capital demanded in each region are as follows:
\begin{equation}
\begin{aligned}
&r^* = \frac{1}{2}\big(\left(B_S + B_L \right) - \left(\tau_S + \tau_L + (2-\alpha_S-\alpha_L)\tau_O\right)\big) - 2\bar{k} \\
&K_S^* = lk_S^* = l\bigg(\bar{k} + \frac{1}{4}\big( (\tau_L - \tau_S - (\alpha_L - \alpha_S)\tau_O ) - (B_L - B_S)\big) \bigg) \\
&K_L^* = lk_L^* = l\bigg(\bar{k} + \frac{1}{4}\big( (\tau_S - \tau_L + (\alpha_L - \alpha_S)\tau_O ) + (B_L - B_S)\big) \bigg) \\
&K_{SS}^* = \frac{2}{3}lk_{SS}^* = \frac{2l}{3}\bigg(\bar{k} + \frac{1}{4}\big( (\tau_L - \tau_S + (2 - \alpha_L - \alpha_S)\tau_O ) - (B_L - B_S)\big) \bigg) \\
&K_{SL}^* = \frac{2}{3}lk_{SL}^* =\frac{2l}{3}\bigg(\bar{k} + \frac{1}{4}\big( (\tau_S - \tau_L + (2 - \alpha_L - \alpha_S)\tau_O ) + (B_L - B_S)\big) \bigg) \\
&K_O^* = \frac{2}{3}lk_O^* = \frac{2l}{3}\left(\bar{k} - \frac{1}{2}(2-\alpha_S-\alpha_L)\tau_O\right)
\end{aligned}
\end{equation}
We denote $B_L - B_S = \theta$, henceforth.
C. Government Objectives and Tax Rates
Given that individuals in the country have identical preferences and inelastically supply one unit of labor to the regional firms, we can infer that all inhabitants receive a common return on capital of $r^*$ eventually, and they use all income to consume private good $c_i$. Hence, the budget constraint for an individual residing in region $i \in \{S, L, O\}$ and the sum of individuals in region $i$ will be
\begin{equation}
\begin{aligned}
c_i &= w_i^* + r^*\bar{k}_i \\
C_i &= \begin{cases}
l(w^*_i + r^*\bar{k}_i) & \text{ for } i \in \{S, L\}\\
\dfrac{2l}{3}(w^*_i + r^*\bar{k}) & \text{ for } i = O
\end{cases}
\end{aligned}
\end{equation}
In addition, we have assumed that the overlapping district is a special district providing a special public good--for example education or health--that the other two districts do not provide. $S$ and $L$ provide their local public goods $G_i$. Then the total public goods provided in region $i$ can be expressed as:
\begin{equation}
\begin{aligned}
G_i &= \begin{cases}
K_i^*\tau_i & \text{ for } i \in \{S, L\}\\
(1-\alpha_S)K_S^*\tau_S + (1-\alpha_L)K_L^*\tau_L & \text{ for } i = O
\end{cases} \\
H_i &= \begin{cases}
(1-\alpha_i)K_i^*\tau_O & \hspace{1.45in} \text{ for } i \in \{S, L\}\\
K_i^*\tau_i & \hspace{1.45in} \text{ for } i = O
\end{cases}
\end{aligned}
\end{equation}
Accordingly, each government in region $i$ chooses $\tau_i$ such that maximizes the following social welfare function, which is represented as the sum of individual consumption and public good provision:
\begin{equation}
\begin{aligned}
& u(C_i, G_i, H_i) \equiv C_i + G_i + H_i
\end{aligned}
\end{equation}
This objective function captures the trade-off faced by governments between attracting capital through lower tax rates and generating revenue for public goods provision. After solving equation (9), we obtain the reaction functions, i.e. the tax rates at the market equilibrium (see Appendix 1 for details):
\begin{equation}
\begin{aligned}
\tau_S^* &= \frac{4\varepsilon}{3} - \frac{\theta}{3} + \frac{\tau_L}{3} - \frac{2-3\alpha_S + \alpha_L}{3}\tau_O \\
\tau_L^* &= -\frac{4\varepsilon}{3} + \frac{\theta}{3} + \frac{\tau_S}{3} - \frac{2-3\alpha_L + \alpha_S}{3}\tau_O \\
\tau_O^* &= \frac{3(\alpha_L + \alpha_S)-4}{(2-(\alpha_L + \alpha_S))(\alpha_L + \alpha_S)}\bar{k} = \Gamma \bar{k}
\end{aligned}
\end{equation}
D. Nash Equilibrium Analysis
The tax rates derived in the previous section represent the optimal response functions for each region. These functions encapsulate each region's best strategy given the strategies of other regions, as each jurisdiction aims to maximize its social welfare function. In essence, these functions delineate the most advantageous tax rate for each region, contingent upon the tax rates set by other regions.
The existence of a Nash equilibrium is guaranteed in our model, as the slopes of the reaction functions are less than unity, satisfying the contraction mapping principle. This ensures that the iterative process of best responses converges to a unique equilibrium point given $\alpha_L$ and $\alpha_S$. The one-shot Nash equilibrium tax rates are given by (see Appendix 2 for details):
\begin{equation}
\begin{aligned}
\tau_S^N &= \varepsilon - \frac{\theta}{4} - \Gamma\left(1-\alpha_S \right)\bar{k} \\
\tau_L^N &= -\left(\varepsilon-\frac{\theta}{4}\right) - \Gamma\left(1-\alpha_L\right)\bar{k} \\
\tau_O^N &= \Gamma\bar{k}
\end{aligned}
\end{equation}
These equilibrium tax rates reveal several important insights. First, the tax rates of regions $S$ and $L$ are influenced by the asymmetry in capital endowments ($\varepsilon$) and productivity ($\theta$), as well as the presence of the overlapping jurisdiction $O$. Second, the overlapping jurisdiction's tax rate is solely determined by the average capital endowment ($\bar{k}$) and the proportion of resources allocated from S and L ($\alpha_S$ and $\alpha_L$). Third, When $\alpha_L + \alpha_S = 4/3$, we have $\tau_O^N = 0$, which effectively reduces our model to a scenario without the overlapping jurisdiction.
The Nash equilibrium also yields equilibrium values for the interest rate and capital demanded in each region:
\begin{equation}
\begin{aligned}
r^N &= \frac{1}{2}\left(B_S + B_L\right) - 2\bar{k} \\
K_S^N &= l\left(\bar{k} - \frac{1}{2}\left(\varepsilon + \frac{\theta}{4} \right)\right) = l\left(\bar{k}_S + \frac{1}{2}\left(\varepsilon - \frac{\theta}{4} \right)\right) \\
K_L^N &= l\left(\bar{k} + \frac{1}{2}\left(\varepsilon + \frac{\theta}{4} \right)\right) = l\left(\bar{k}_L - \frac{1}{2}\left(\varepsilon -
\frac{\theta}{4} \right)\right) \\
K_{SS}^N &= \frac{2l}{3}\left(\bar{k} + \frac{1}{2}\bar{k}\Gamma(1-\alpha_S) - \frac{1}{2}\left(\varepsilon + \frac{\theta}{4} \right)
\right) = \alpha_S K_S^N \\
K_{SL}^N &= \frac{2l}{3}\left(\bar{k} + \frac{1}{2}\bar{k}\Gamma(1-\alpha_L) + \frac{1}{2}\left(\varepsilon + \frac{\theta}{4} \right) \right) = \alpha_L K_L^N \\
K_O^N &= \frac{l}{3}\cdot\frac{4 -\alpha_L - \alpha_S}{\alpha_L + \alpha_S}\bar{k}
\end{aligned}
\end{equation}
These equilibrium conditions lead to two key lemmas that characterize the behavior of our model:
LEMMA 1 (Net Capital Position): The sign of $\Phi \equiv \varepsilon - \frac{\theta}{4}$ determines the net capital position of regions S and L. When $\Phi > 0$, L is a net capital exporter and S is a net capital importer, and vice versa when $\Phi < 0$.
PROOF:
From equation (12), we can see that:
\begin{align*}
K_L^N - K_S^N &= l\left(\left(\bar{k} + \frac{1}{2}\left(\varepsilon + \frac{\theta}{4} \right)\right) - \left(\bar{k} - \frac{1}{2}\left(\varepsilon + \frac{\theta}{4} \right)\right)\right) \\
&= l\left(\varepsilon + \frac{\theta}{4}\right)
\end{align*}
The sign of this difference is determined by $\varepsilon - \frac{\theta}{4} \equiv \Phi$.
LEMMA 2 (Overlapping Jurisdiction’s Effectiveness): The sign of $\Gamma \equiv \frac{3\left( \alpha_{L} + \alpha_{S} \right) - 4}{\left( 2 - \left( \alpha_{L} + \alpha_{S} \right) \right)\left( \alpha_{L} + \alpha_{S} \right)}$ determines the effective tax rate of O. Moreover, $\alpha_{L} + \alpha_{S}$ must be greater than 4/3 for O to provide a positive sum of special public good H.
PROOF:
From equation (11), we see that the sign of $\tau_O^N$ is determined by the sign of $\Gamma$. The numerator of $\Gamma$ is positive when $\alpha_{L} + \alpha_{S} > 4/3$, and the denominator is always positive for $\alpha_{L} + \alpha_{S} < 2$. Therefore, $\Gamma > 0$ (and consequently $\tau_O^N > 0$) when $\alpha_{L} + \alpha_{S} > 4/3$.
These lemmas provide crucial insights into the dynamics of our model. First, the introduction of the overlapping jurisdiction $O$ does not alter the net capital positions of $S$ and $L$ compared to a scenario without $O$. The capital flow between $S$ and $L$ is determined solely by the relative strengths of their capital endowments ($\varepsilon$) and productivity differences ($\theta$). In addition, the effectiveness of the overlapping jurisdiction in providing public goods is contingent on receiving a sufficient allocation of resources from $S$ and $L$.
These findings contribute to our understanding of tax competition in multi-layered jurisdictional settings and provide a foundation for analyzing the welfare implications of overlapping administrative structures.
IV. Simulations and Results
To better understand the implications of our theoretical model and address the research questions posed in the introduction, we conducted a series of simulations. These simulations allow us to visualize the non-linear relationships between key variables and provide insights into the strategic behavior of jurisdictions in our overlapping tax competition model.
A. Net Capital Positions and Tax Competition Dynamics
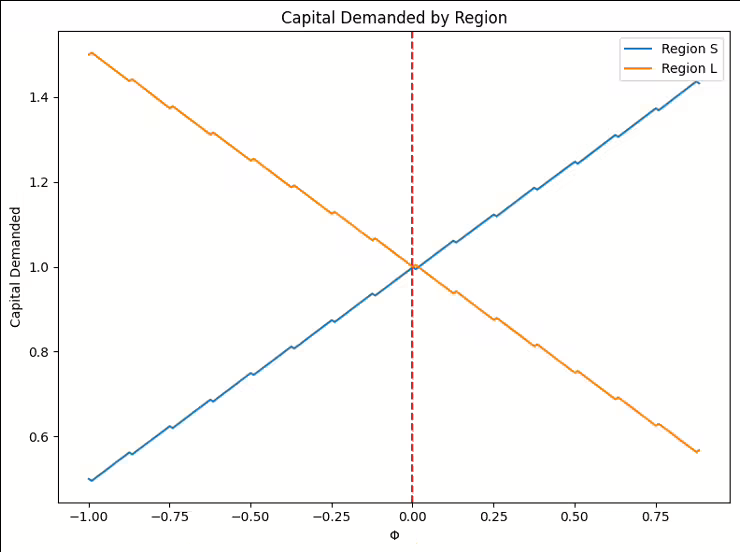
Our first simulation focuses on the net capital positions of regions $S$ and $L$, as determined by the parameter $\Phi \equiv \varepsilon - \theta/4$. Figure 2 illustrates how changes in $\Phi$ affect the capital demanded by each region.
As shown in Figure 2, when $\Phi > 0$, region $L$ becomes a net capital exporter, while region $S$ becomes a net capital importer. This result directly addresses our first research question about how overlapping administrative divisions affect strategic tax-setting behavior. The presence of the overlapping jurisdiction $O$ does not alter the net capital positions of $S$ and $L$ compared to a scenario without $O$.
However, it does influence their tax-setting strategies, as evidenced by the Nash equilibrium tax rates in equation (12). These equations show that $S$ and $L$ adjust their tax rates in response to the overlapping jurisdiction $O$ by factors of $\Gamma(1-\alpha_S)\bar{k}$ and $\Gamma(1-\alpha_L)\bar{k}$, respectively. This strategic adjustment demonstrates how the presence of an overlapping jurisdiction alters tax-setting behavior, even when it doesn't change net capital positions.
B. Public Good Provision and Welfare Implications
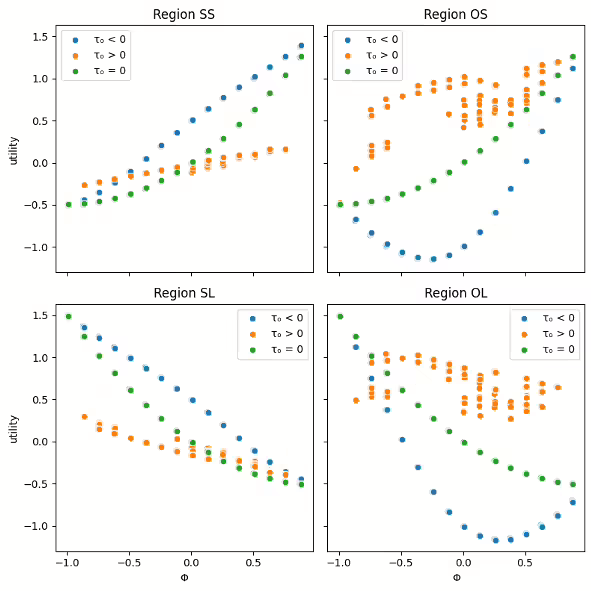
Then, we examine the utility derived from public goods by representative residents in each region. Figure 3 visualizes these utilities across different values of $\Phi$ and $\tau_O$.
Figure 3 reveals several important insights. First, the utility derived from public goods varies significantly across sub-regions ($SS$, $SL$, $OS$, $OL$), highlighting the complex welfare implications of overlapping jurisdictions. Second, the overlapping region $O$'s tax rate ($\tau_O$) has a substantial impact on the utility derived from public goods, especially in the overlapping sub-regions $OS$ and $OL$. Third, the relationship between $\Phi$ and public good utility is non-linear and differs across regions, suggesting that the welfare implications of tax competition are not uniform. These findings suggest that the presence of an overlapping jurisdiction can lead to heterogeneous welfare effects.
C. The Role of the Overlapping Jurisdiction
Our model and simulations highlight the crucial role played by the overlapping jurisdiction $O$. The tax rate of $O$ ($\tau_O^N = \Gamma\bar{k}$) is determined by the proportion of resources allocated from the primary economies ($\alpha_S$ and $\alpha_L$), or specifically $\Gamma$. This relationship reveals that the overlapping jurisdiction's ability to provide public goods ($H$) is contingent on receiving a sufficient proportion of resources from $S$ and $L$. Specifically, $\alpha_L + \alpha_S$ must exceed $4/3$ for $O$ to provide a positive sum of special public goods.
This finding has important implications for the design of multi-tiered governance systems. It suggests that overlapping jurisdictions need a critical mass of resource allocation to function effectively, which may inform decisions about the creation and empowerment of special-purpose districts or other overlapping administrative structures.
V. Conclusion
This study has examined the dynamics of tax competition in regions with overlapping tax jurisdictions, leveraging game theory to develop a theoretical framework for understanding these administrative structures. By constructing a simplified model and deriving Nash equilibrium conditions, we have identified several key insights that contribute to the existing literature on tax competition. Our analysis reveals that while the introduction of an overlapping jurisdiction does not alter the net capital positions of the primary regions, it leads to strategic adjustments in tax rates. This finding extends the traditional models of tax competition by incorporating the complexities of multi-tiered governance structures.
The effectiveness of the overlapping jurisdiction in providing public goods is found to be contingent on receiving a sufficient allocation of resources from the primary regions. Moreover, our simulations demonstrate that the presence of overlapping jurisdictions can lead to heterogeneous welfare effects across sub-regions, challenging the uniform predictions of traditional tax competition models and suggesting the need for more nuanced policy approaches.
While our study provides valuable insights, it is important to acknowledge its limitations. The use of a simplified model, while allowing for tractable analysis, inevitably omits some real-world complexities. Factors such as population mobility, diverse tax bases, and income disparities among residents were not incorporated into the model. Furthermore, our analysis is static, which may not capture the dynamic nature of tax competition and capital flows over time. The assumption of identical preferences for public goods across all residents may not reflect the heterogeneity of preferences in real-world settings. Additionally, the model assumes perfect information among all players, which may not hold in practice where information asymmetries can influence strategic decisions.
To address these limitations and further advance our understanding of tax competition in a wide array of administrative structures, several avenues for future research are proposed. Developing dynamic models that capture the evolution of tax competition over time, potentially using differential game theory approaches, could provide insights into the long-term implications of overlapping jurisdictions. Incorporating heterogeneous preferences for public goods among residents would allow for a more nuanced examination of how diverse citizen demands affect tax competition and public good provision in overlapping jurisdictions.
Empirical studies using data from regions with overlapping jurisdictions, such as special districts in the United States, could test the predictions of our theoretical model and provide valuable real-world validation. Extending the model to include various policy interventions, such as intergovernmental transfers or tax harmonization efforts, could help evaluate their effectiveness in mitigating potential inefficiencies. Incorporating insights from behavioral economics to account for bounded rationality and other cognitive factors may provide a more realistic representation of tax-setting behavior in complex jurisdictional settings.
In conclusion, this study provides a theoretical foundation for understanding tax competition in regions with overlapping jurisdictions. By highlighting the complex interactions between multiple layers of government, our findings contribute to the broader literature on fiscal federalism and public economics. As urbanization continues and governance structures become increasingly complex, the insights derived from this research can inform policy discussions on decentralization, local governance structures, and intergovernmental fiscal relations. Future work in this area has the potential to significantly enhance our understanding of modern urban governance and contribute to the development of more effective and equitable fiscal policies in multi-tiered administrative structures.
References
[1] C. M. Tiebout, “A pure theory of local expenditures,” Journal of Political Economy, vol. 64, no. 5, pp. 416–424, 1956.
[2] W. E. Oates, Fiscal federalism. Harcourt Brace Jovanovich, 1972.
[3] G. Brennan and J. M. Buchanan, The power to tax: Analytical foundations of a fiscal constitution. Cambridge University Press, 1980.
[4] J. D. Wilson, “A theory of interregional tax competition,” Journal of Urban Economics, vol. 19, no. 3, pp. 296–315, 1986.
[5] G. R. Zodrow and P. Mieszkowski, “Pigou, tiebout, property taxation, and the underprovision of local public goods,” Journal of Urban Economics, vol. 19, no. 3, pp. 356–370, 1986.
[6] D. E. Wildasin, “Nash equilibria in models of fiscal competition,” Journal of Public Economics, vol. 35, no. 2, pp. 229–240, 1988.
[7] R. Kanbur and M. Keen, “Jeux sans fronti`eres: Tax competition and tax coordination when countries differ in size,” American Economic Review, pp. 877–892, 1993.
[8] J. A. DePater and G. M. Myers, “Strategic capital tax competition: A pecuniary externality and a corrective device,” Journal of Urban Economics, vol. 36, no. 1, pp. 66–78, 1994.
[9] O. Hochman, D. Pines, and J.-F. Thisse, “On the optimality of local government: The effects of metropolitan spatial structure,” Journal of Economic Theory, vol. 65, no. 2, pp. 334–363, 1995.
[10] A. Esteller-Mor´e and A. Sol´e-Oll´e, “Vertical income tax externalities and fiscal interdependence: Evidence from the us,” Regional Science and Urban Economics, vol. 31, no. 2-3, pp. 247–272, 2001.
[11] M. Keen and C. Kotsogiannis, “Does federalism lead to excessively high taxes?” American Economic Review, vol. 92, no. 1, pp. 363–370, 2002.
[12] J.-i. Itaya, M. Okamura, and C. Yamaguchi, “Are regional asymmetries detrimental to tax coordination in a repeated game setting?” Journal of Public Economics, vol. 92, no. 12, pp. 2403–2411, 2008.
[13] L. P. Feld, G. Kirchg¨assner, and C. A. Schaltegger, “Decentralized taxation and the size of government: Evidence from swiss state and local governments,” Southern Economic Journal, vol. 77, no. 1, pp. 27–48, 2010.
[14] H. Ogawa and W. Wang, “Asymmetric tax competition and fiscal equalization in a repeated game setting,” International Tax and Public Finance, vol. 23, no. 6, pp. 1035–1064, 2016.
APPENDIX 1 - DERIVING REACTION FUNCTIONS
Let us get the partial derivatives that are needed to get the first order condition of social utility function. Starting with the easier ones,
\begin{align*}
&\frac{\partial K^*_S}{\partial \tau_S} = -\frac{l}{4}, \quad \frac{\partial K^*_L}{\partial \tau_L} = -\frac{l}{4}
, \quad \frac{\partial K^*_O}{\partial \tau_O} = -\frac{l}{3}\left(2-\alpha_L - \alpha_S\right).
\end{align*}
Partial differentiation of $r^*$ with respect to the tax rates are
\begin{align*}
\frac{\partial r^*}{\partial \tau_S} = -\frac{1}{2}, \quad \frac{\partial r^*}{\partial \tau_L} = -\frac{1}{2}, \quad \frac{\partial r^*}{\partial \tau_O} = -\frac{2- (\alpha_L + \alpha_S)}{2}.
\end{align*}
Then, the partial differentiation of $w^*_i$ with respect to respective tax rates are:
\begin{align*}
\frac{\partial w^*_S}{\partial \tau_S} &= 2 \left(\frac{K^*_S}{l}\right)\cdot \frac{\partial K_S^*/l}{\partial \tau_S} = -\frac{K^*_S}{2l} \\
\frac{\partial w^*_L}{\partial \tau_L} &= 2 \left(\frac{K^*_L}{l}\right)\cdot \frac{\partial K_L^*/l}{\partial \tau_L} = -\frac{K^*_L}{2l} \\
\frac{\partial w^*_O}{\partial \tau_O} &= 3 \left(\frac{K^*_O}{l}\right)\cdot \frac{\partial 3K_O^*/2l}{\partial \tau_O} = -\frac{3(2-\alpha_L - \alpha_S)K_O^*}{2l}.
\end{align*}
Furthermore,
\begin{align*}
&\frac{\partial K^*_S\tau_S}{\partial \tau_S} = K^*_S -\frac{l}{4}\tau_S, \quad \frac{\partial K^*_L\tau_L}{\partial \tau_L} = K^*_L -\frac{l}{4}\tau_L, \quad \frac{\partial K^*_O\tau_O}{\partial \tau_O} = K^*_O -\frac{l}{3}\left(2-\alpha_L - \alpha_S\right)\tau_O.
\end{align*}
Lastly, we have
\begin{align*}
\frac{\partial(1-\alpha_S)\tau_O K^*_S}{\partial \tau_S} &= - \frac{l}{4}(1-\alpha_S)\tau_O \\
\frac{\partial(1-\alpha_L)\tau_O K^*_L}{\partial \tau_L} &= - \frac{l}{4}(1-\alpha_L)\tau_O
\end{align*}
Summing up, the first order condition for the social utility functions of region $S$ and $L$ are:
\begin{align*}
\frac{\partial U_S}{\partial \tau_S} = l\left(-\frac{K^*_S}{2l} -\frac{\bar{k}_S}{2}\right) + K^*_S -\frac{l}{4}\tau_S - \frac{l}{4}(1-\alpha_S)\tau_O = 0 \\
\frac{\partial U_L}{\partial \tau_L} = l\left(-\frac{K^*_L}{2l} -\frac{\bar{k}_L}{2}\right) + K^*_L -\frac{l}{4}\tau_L - \frac{l}{4}(1-\alpha_L)\tau_O = 0
\end{align*}
Rearranging the terms, we see that
\begin{align*}
\tau_S &= -(1-\alpha_S)\tau_O + 2\left(k_S^* -\bar{k}_S\right) \\
&= -(1-\alpha_S)\tau_O + 2\bigg(\varepsilon + \frac{1}{4}\big((\tau_L - \tau_S - (\alpha_L - \alpha_S)\tau_O ) - (B_L - B_S)\big) \bigg) \\
&\iff \tau_S^* = \frac{4\varepsilon}{3} - \frac{\theta}{3} + \frac{\tau_L}{3} - \frac{2-3\alpha_S + \alpha_L}{3}\tau_O \\
\tau_L &= -(1-\alpha_L)\tau_O + 2\left(k_L^* -\bar{k}_L\right) \\
&= -(1-\alpha_L)\tau_O + 2\bigg(-\varepsilon + \frac{1}{4}\big((\tau_S - \tau_L + (\alpha_L - \alpha_S)\tau_O ) + (B_L - B_S)\big) \bigg) \\
&\iff \tau_L^* = -\frac{4\varepsilon}{3} + \frac{\theta}{3} + \frac{\tau_S}{3} - \frac{2-3\alpha_L + \alpha_S}{3}\tau_O.
\end{align*}
The FOC for the social utility function of region $O$ is:
\begin{align*}
&\frac{2l}{3}\left(-\frac{3(2-\alpha_L - \alpha_S)K_O^*}{2l} - \frac{2- (\alpha_L + \alpha_S)}{2}\bar{k}\right) + K^*_O -\frac{l}{3}\left(2-\alpha_L - \alpha_S\right)\tau_O = 0 \\
& \iff \tau_O^* = \frac{3(\alpha_L + \alpha_S)-4}{(2-\alpha_L - \alpha_S)(\alpha_L + \alpha_S)}\bar{k} = \Gamma \bar{k}%= \frac{2-3\alpha}{\alpha(2-\alpha)}\bar{k}
\end{align*}
APPENDIX 2 - DERIVING NASH EQUILIBRIUM
Let $\gamma_S$ and $\gamma_L$ be $\Gamma \cdot (2-3\alpha_S + \alpha_L)/3$ and $\Gamma \cdot (2-3\alpha_L + \alpha_S)/3$, respectively. Then,
\begin{align*}
\tau_S &= \frac{4\varepsilon}{3} - \frac{\theta}{3} + \frac{1}{3}\left(-\frac{4\varepsilon}{3} + \frac{\theta}{3} + \frac{\tau_S}{3} - \gamma_L\bar{k}\right) - \gamma_S\bar{k} \\
&= \frac{8\varepsilon}{9} - \frac{2\theta}{9} + \frac{1}{9}\tau_S - \left(\frac{\gamma_L}{3} + \gamma_S\right)\bar{k}\\
&\iff \tau_S^N = \varepsilon - \frac{\theta}{4} - \Gamma\left(1-\alpha_S \right)\bar{k}\\
\tau_L^N &= -\left(\varepsilon-\frac{\theta}{4}\right) - \Gamma\left(1-\alpha_L\right)\bar{k}\\
\tau_O^N &= \Gamma\bar{k}
\end{align*}
It follows that
\begin{align*}
\tau_L^N - \tau_S^N &= -2\left(\varepsilon - \frac{\theta}{4}\right) + \Gamma(\alpha_L - \alpha_S)\bar{k}\\
\tau_S^N - \tau_L^N &= 2\left(\varepsilon - \frac{\theta}{4}\right) + \Gamma(\alpha_S - \alpha_L)\bar{k}
\end{align*}
Plugging them in, the interest rates and capital demanded in each region are:
\begin{align*}
r^N &= \frac{1}{2}\left(B_S + B_L\right) - 2\bar{k}\\
K_S^N &= l\left(\bar{k} - \frac{1}{2}\left(\varepsilon + \frac{\theta}{4} \right)\right) = l\left(\bar{k}_S + \frac{1}{2}\left(\varepsilon - \frac{\theta}{4} \right)\right)\\
K_L^N &= l\left(\bar{k} + \frac{1}{2}\left(\varepsilon + \frac{\theta}{4} \right)\right) = l\left(\bar{k}_L - \frac{1}{2}\left(\varepsilon - \frac{\theta}{4} \right)\right)\\
K_{SS}^N &= \frac{2l}{3}\left(\bar{k} + \frac{1}{2}\bar{k}\Gamma(1-\alpha_S) - \frac{1}{2}\left(\varepsilon + \frac{\theta}{4} \right) \right)\\
K_{SL}^N &= \frac{2l}{3}\left(\bar{k} + \frac{1}{2}\bar{k}\Gamma(1-\alpha_L) + \frac{1}{2}\left(\varepsilon + \frac{\theta}{4} \right) \right)\\
K_O^N &= \frac{l}{3}\cdot\frac{4 -\alpha_L - \alpha_S}{\alpha_L + \alpha_S}\bar{k}
\end{align*}
How is Korea’s Blood Supply Maintained? - Effects of the COVID-19 Pandemic, Blood Shortage Periods, and Promotions on Blood Supply Dynamics
How is Korea’s Blood Supply Maintained? - Effects of the COVID-19 Pandemic, Blood Shortage Periods, and Promotions on Blood Supply Dynamics
Published
Donggyu Kim*
* Swiss Institute of Artificial Intelligence, Chaltenbodenstrasse 26, 8834 Schindellegi, Schwyz, Switzerland
Abstract
This study quantitatively assesses the effects of the COVID-19 pandemic, blood shortage periods, and promotional activities on blood supply and usage in Korea. Multiple linear regression analysis was conducted using daily blood supply, usage, and stock data from 2018 to 2023, incorporating various control variables. Findings revealed that blood supply decreased by 5.11% and blood usage decreased by 4.25% during the pandemic. During blood shortage periods, blood supply increased by 3.96%, while blood usage decreased by 1.98%. Although the signs of the estimated coefficients aligned with those of a previous study [1], their magnitudes differed. Promotional activities had positive effects on blood donation across all groups, but the magnitude of the impact varied by region and gender. Special promotions offering sports viewing tickets were particularly effective. This study illustrates the necessity of controlling exogenous variables to accurately measure their effects on blood supply and usage, which are influenced by various social factors. The findings underscore the importance of systematic promotion planning and suggest the need for tailored strategies across different regions and demographic groups to maintain a stable blood supply.
1. Introduction
Blood transfusion is an essential treatment method used in emergencies, for certain diseases, and during surgeries. Blood required for transfusion cannot be substituted with other substances and has a short shelf life. Additionally, it experiences demand surges that are difficult to predict. Therefore, systematic management of blood stock is required. Blood stock is determined by blood usage and the number of blood donors. Thus, understanding the relationship between usage and supply, as well as the effect of promotions, is essential for effective blood stock management.
There is a paucity of quantitative research on blood supply dynamics during crises and the effects of promotional activities. This study aims to address this research gap. Previous studies in Korea on blood donation have primarily focused on qualitative analysis to identify motives for blood donation through surveys.[2][3][4][5] Kim (2015)[6] used multiple linear regression analysis to predict the number of donations for individual donors but used the personal information of each donor as explanatory variables and did not consider time series characteristics. For this reason, understanding the dynamics of the total number of donors was difficult. Kim (2023)[1] studied the impact of the COVID-19 epidemic on the number of blood donations but did not control exogenous variables and types of blood donation.
This study aims to quantify the effects of the COVID-19 pandemic and blood shortage periods on blood supply and usage. Additionally, it measures the quantitative effects of various promotions on the number of blood donors. To achieve these objectives, regression analysis was utilized with control variables, enabling more precise estimations than previous studies. Based on these findings, this paper proposes effective blood management methods.
2. Methodology
2.1. Research Subjects
According to the Blood Management Act[7], blood can be collected at medical institutions, the Korean Red Cross Blood Services, and the Hanmaeum Blood Center. According to the Annual Statistical Report[8], blood donations conducted by the Korean Red Cross accounted for 92% of all blood donations in 2022. This study uses blood donation data from the Korean Red Cross Blood Services, which accounts for the majority of the blood supply.
2.2. Data Sources
The data for the number of blood donors by location utilized in this study were obtained from the Annual Statistical Report on Blood Services.[8] The daily data on the number of blood donors, blood usage, blood stock, and promotion dates were provided by the Korean Red Cross Blood Services[9].
The data for the number of blood donors, blood usage, and blood stock used in the study cover the period from January 1, 2018, to July 31, 2023, and the promotion date data cover the period from January 1, 2021, to July 31, 2023. Temperature and precipitation data were obtained from the Korea Meteorological Administration’s Automated Synoptic Observing System (ASOS) [10].
2.3. Variable Definitions
In this study, the number of blood donors, or blood supply, is defined as the number of whole blood donations at the Korean Red Cross. The COVID-19 pandemic period is defined as the duration from January 20, 2020, (the first case in Korea) to March 1, 2022 (the end of the vaccine pass operation). Red blood cell product stock is defined as the sum of concentrated red blood cells, washed red blood cells, leukocyte-reduced red blood cells, and leukocyte-filtered red blood cell stock.
Blood usage is based on the quantity of red blood cell products supplied by the Korean Red Cross to medical institutions. The regions in the study are divided according to the jurisdictions of the blood centers under the Korean Red Cross Blood Service and do not necessarily coincide with Korea’s administrative districts. Data from the Seoul Central, Seoul Southern, and Seoul Eastern Blood Centers were integrated and used as Seoul.
Weather information for each region is based on measurements from the nearest weather observation station to the blood center, and the corresponding Observation point numbers for each region are listed in Table 1.
Public holidays are based on the Special Day Information[11] from the Korea Astronomy and Space Science Institute.
\begin{array}{l|r}
\hline
\textbf{Blood center name} & \textbf{Observation station number} \\
\hline
\text{Seoul} & 108 \\
\text{Busan} & 159 \\
\text{Daegu/Gyeongbuk} & 143 \\
\text{Incheon} & 112 \\
\text{Ulsan} & 152 \\
\text{Gyeonggi} & 119 \\
\text{Gangwon} & 101 \\
\text{Chungbuk} & 131 \\
\text{Daejeon/Sejong/Chungnam} & 133 \\
\text{Jeonbuk} & 146 \\
\text{Gwangju/Jeonnam} & 156 \\
\text{Gyeongnam} & 255 \\
\text{Jeju} & 184 \\
\hline
\end{array}
Table 1. Observation Station number for each Blood Center
2.4. Variable Composition
Dependent Variable Plasma donations, 67% of which are used for pharmaceutical raw materials[8], can be imported due to their long shelf life of 1 year.[7] Also, in the case of platelet and multi-component blood donation, 95% of donors are male[8], and a decent number of days have no female blood donors, affecting the analysis. For these reasons, this study used the number of whole-blood donors as the target variable. Additionally, the amount of collected blood is determined by an individual’s physical condition[7], not by preference. Therefore, it is integrated within gender groups.
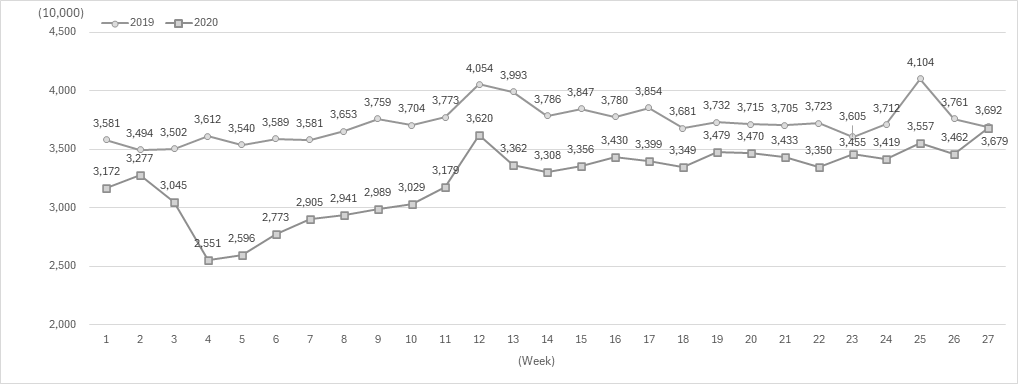
Explanatory Variables Considering the differences in operating hours of blood donation centers on weekdays, weekends, and holidays as shown in Figure 1, variables indicating the day of week and holiday were considered.
Table 2 shows that there are differences between regions on blood donation. Considering this, region was used as a control variable.
The annual seasonal effects are not controlled by the holidays variable alone. for this reason, Fourier terms were introduced as explanatory variables [12].
\begin{array}{l|r|r|r}
\hline
\textbf{Blood center name}& \textbf{Population} & \textbf{Blood donation} & \textbf{Blood donation ratio (%)} \\
\hline
\text{Total} & 51,439,038 & 2,649,007 & 5.1 \\
\hline
\text{Seoul} & 9,428,372 & 846,646 & 9.0 \\
\text{Busan} & 3,317,812 & 204,250 & 6.2 \\
\text{Daegu/Gyeongbuk} & 4,964,183 & 225,245 & 4.5 \\
\text{Incheon} & 2,967,314 & 170,777 & 5.8 \\
\text{Ulsan} & 13,589,432 & 217,008 & 1.6 \\
\text{Gyeonggi} & 1,536,498 & 124,866 & 8.1 \\
\text{Gangwon} & 1,595,058 & 83,820 & 5.3 \\
\text{Chungbuk} & 3,962,700 & 237,169 & 6.0 \\
\text{Daejeon/Sejong/Chungnam} & 1,769,607 & 96,992 & 5.5 \\
\text{Jeonbuk} & 3,248,747 & 189,559 & 5.8 \\
\text{Gwangju/Jeonnam} & 3,280,493 & 123,250 & 3.8 \\
\text{Gyeongnam} & 1,110,663 & 87,677 & 7.9 \\
\text{Jeju} & 678,159 & 41,748 & 6.2 \\
\hline
\end{array}
Table 2. Blood donation rate by region[8]
$$X_{sin_{ij}} = \sin \left( \frac{2\pi \operatorname{doy}(bd)_{i}}{365}j \right),\quad X_{cos_{ij}} = \cos\left( \frac{2\pi \operatorname{doy}(bd)_{i}}{365}j \right)$$
Where $\operatorname{doy}\text{(01-01-yyyy)} = 0,\dots, \operatorname{doy}\text{(12-31-yyyy)} = 364$
$j$ is a hyperparameter setting the number of Fourier terms added. $j = 1,\dots,6$ terms with optimal AIC[13] were added to the model.
According to Table 2, 70% of all blood donors visit blood donation centers to donate. Therefore, to control the influence of weather conditions[14] that affect the pedestrian volume and the number of blood donors, a precipitation variable was included. Meanwhile, the temperature variable, which has a strong relationship with the season, was already controlled by Fourier terms and was found to be insignificant, so it was excluded from the explanatory variables.
\begin{array}{l|r}
\hline
\textbf{Blood donation place} & \textbf{Ratio} \\
\hline
\text{Individual, blood donation center} & 74.8\% \\
\text{Individual, street} & 0.3\% \\
\text{Group} & 24.9\% \\
\hline
\end{array}
Table 3. Ratio of blood donation by place
The Public-Private Joint Blood Supply Crisis Response Manual[15] specifies blood usage control measures during crises (Table 4). To reflect the effect of crises in the model, a blood shortage day variable was created and introduced as a proxy for the crisis stage.
A blood shortage day is defined as a day when the daily blood stock is three times less than the average daily usage in the previous year, as well as the following 7 days. The mathematical expression is as follows:
\begin{array}{l|r}
\hline
\textbf{Category} & \textbf{Criteria} \\
\hline
\text{Interest} & (bs) < 5 \times (bu)_{prev\, year} \\
\text{Cautious} & (bs) < 3 \times (bu)_{prev\, year} \\
\text{Alert} & (bs) < 2 \times (bu)_{prev\, year} \\
\text{Serious} & (bs) < 1 \times (bu)_{prev\, year} \\
\hline
\end{array}
Table 4. Criteria for blood supply crisis stage[15]
Where $(bs)$ is the blood stock and $(bu)$ is the blood usage
$$(bu)_{prev\, year}[(bu)_{i}] := \frac{1}{365}\sum_{\{j|\operatorname{year}[(bu)_{j}]= \operatorname{year}[(bu)_{i}]-1\}}(bu)_{j}$$
$$C_{i} := \mathbf{1}\left[ (bs)_{i} < 3 \times (bu)_{prev\, year}[(bu)_{i}] \right]$$
$$D_{short, i}:= \operatorname{sgn}[\sum\limits_{j=i-6}^{i} C_{j}]$$
According to Figure 2, population movement decreased during the COVID-19 pandemic, and blood donation was not allowed for a certain period after COVID recovery or vaccination.[7] Bae (2021)[16] showed factors that affected the decrease in blood donors during this period. Kim (2023)[1] also showed that there was a decrease in blood donation during this period. To control the effect of the pandemic, COVID-19 pandemic period dummy variables were introduced.
2.5. Research Method
To analyze the effects of promotions according to region and gender, this study conducted multiple regression analyses. The OLS model was chosen because it clearly shows the linear relationship between variables, and the results are highly interpretable.
Control variables were used to derive accurate estimates. The model’s accuracy was confirmed through the estimated effect of the COVID-19 and blood shortage period variables, consistent with the prior studies.
\begin{array}{l|r}
\hline
\textbf{Variable Name} & \textbf{Description} \\
\hline
D_{dow_{ij}} = \mathbf{1}[\operatorname{dow}(bd_{i}) = j] & \text{Day of week dummies} \\
\text{where} \operatorname{dow}\text{(monday)}=0, \dots, \operatorname{dow}\text{(sunday)}=6 & \\
\hline
D_{hol} & \text{Holiday dummy} \\
\hline
D_{short} & \text{Shortage day dummy} \\
\hline
D_{cov\, week} & \text{COVID pandemic weekday dummy} \\
\hline
D_{cov\, sat} & \text{COVID pandemic Saturday dummy} \\
\hline
D_{cov\, sun} & \text{COVID pandemic Sunday dummy} \\
\hline
X_{sin_{ij}} = \sin\left(\frac{2\pi \operatorname{doy}(bd_{i})}{365}\right) \\
X_{cos_{ij}} = \cos\left(\frac{2\pi \operatorname{doy}(bd_{i})}{365}\right) & \text{Fourier terms for yearly seasonality} \\
\text{where} \operatorname{doy}\text{(01-01-yyyy)} = 0, \dots, \operatorname{doy}\text{(12-31-yyyy)} = 364 & \\
\hline
X_{rain\, fall, r} & \text{Precipitation in region r} \\
\hline
D_{promo} & \text{Promotion dummy} \\
\hline
D_{special\, promo} & \text{Special promotion dummy} \\
\hline
\end{array}
Table 5. Variable Description
The proposed model for the number of blood donors is expressed as an OLS model, as shown in Equation (1). The model for blood usage is also defined using the same explanatory variables.
\begin{equation}\begin{aligned}
bd_{i} &= \sum\limits_{j=0}^{6}\beta_{dow_{j}}D{dow_{ij}} + \beta_{h}D_{hol} + \beta_{s}D_{short}\\
&+ \beta_{cw}D_{cov\, week_{i}} + \beta_{c\, sat}D_{cov\, sat_{i}} + \beta_{c\, sun}D_{cov\, sun_{i}}\\
&+ \sum\limits_{j=1}^{7}(\beta_{cos_{j}}X_{cos_{ij}} + \beta_{sin_{j}}X_{sin_{ij}}) + D_{promo} + D_{special\, promo}
\end{aligned}\tag{1}\label{eq1}
\end{equation}
The model considering regional characteristics is shown in Equation \eqref{eqn:bd_region}, where $r$ represents each region.
\begin{equation}\begin{aligned}\label{eqn:bd_region}
bd_{i,r} &= \sum\limits_{j=0}^{6}\beta_{dow_{j, r}}D_{dow_{ij}} + \beta{h, r}D_{hol} + \beta_{s, r}D_{short}\\
&+ \beta_{cw, r}D_{cov\, week_{i}} + \beta{c\, sat, r}D_{cov\, sat_{i}} + \beta{c\, sun, r}D_{cov\, sun_{i}}\\
&+ \sum\limits_{j=1}^{7}(\beta_{\cos_{j}, r}X_{\cos_{ij}} + \beta_{\sin_{j}, r}X_{\sin_{ij}}) + X_{rain\, fall, r} + D_{promo} + D_{special\, promo}
\end{aligned}\tag{2}\label{eq2}
\end{equation}
3. Result and Discussion
The regression results presented in Tables 6 and 7 reveal patterns in blood supply and usage dynamics. The day of the week significantly influences both supply and demand, also holidays have a substantial negative impact. The high R-squared value (0.902) of the blood usage model suggests that it accounts for most of the variability in blood usage.
\begin{array}{lcccc}
\hline
& & \textbf{Blood Supply Model Summary} & & \\
\hline
\text{R-squared} & 0.657 & \text{Adj. R-squared} & 0.653 \\
\hline
& coef & std err & t-value & \texttt{P>|t|} \\
mon & 5818.4625 & 52.319 & 111.211 & 0.000 \\
tue & 5660.4049 & 52.225 & 108.385 & 0.000 \\
wed & 5776.1600 & 52.270 & 110.507 & 0.000 \\
thu & 5704.9131 & 52.033 & 109.641 & 0.000 \\
fri & 6587.9064 & 52.282 & 126.008 & 0.000 \\
sat & 5072.4046 & 62.301 & 81.417 & 0.000 \\
sun & 3211.1523 & 62.386 & 51.472 & 0.000 \\
holiday & -3116.7659 & 92.486 & -33.700 & 0.000 \\
shortage & 214.1011 & 85.250 & 2.511 & 0.012 \\
cov\_weekday& -482.9943 & 45.439 & -10.629 & 0.000 \\
cov\_sat & 280.2871 & 101.498 & 2.762 & 0.006 \\
cov\_sun & 128.8915 & 100.873 & 1.278 & 0.201 \\
sin\_1 & -2.1102 & 26.913 & -0.078 & 0.938 \\
cos\_1 & 34.2147 & 26.223 & 1.305 & 0.192 \\
sin_2 & -175.5033 & 26.685 & -6.577 & 0.000 \\
cos\_2 & 0.0618 & 26.736 & 0.002 & 0.998 \\
sin\_3 & 94.0805 & 26.947 & 3.491 & 0.000 \\
cos\_3 & 59.8794 & 26.371 & 2.271 & 0.023 \\
sin\_4 & -37.4031 & 26.410 & -1.416 & 0.157 \\
cos\_4 & -158.1612 & 26.401 & -5.991 & 0.000 \\
sin\_5 & -84.8483 & 26.622 & -3.187 & 0.001 \\
cos\_5 & -2.8368 & 26.699 & -0.106 & 0.915 \\
sin\_6 & 102.8305 & 26.498 & 3.881 & 0.000 \\
cos\_6 & -53.5580 & 26.240 & -2.041 & 0.041 \\
sin\_7 & -90.8545 & 26.299 & -3.455 & 0.001 \\
cos\_7 & 3.4063 & 26.318 & 0.129 & 0.897 \\
\hline
\end{array}
Table 6. Summary of blood supply model
While the relatively lower R-squared value (0.657) of the blood supply model indicates that it is influenced by various random social effects.
3.1. Impact of the COVID-19 Pandemic
Table 7 shows that blood usage decreased by 4.25% during the COVID-19 pandemic period. This includes not only the man-made decrease in the supply due to the blood shortage but also the impact on the demand, where surgeries were reduced due to COVID- 19. Table 6 shows that blood supply also decreased by 5.11% during the same period.
3.2. Impact of Blood Shortage Periods
During blood shortage periods, blood usage decreased by 1.98% (Table 7), while blood supply increased by 3.96% (Table 6) due to conservation efforts and increased donations. This result reflects the efforts made by medical institutions to adjust blood usage and the impact of blood donation promotion campaigns in response to blood shortage situations.
\begin{array}{lcccc}
\hline
& & \textbf{Blood Usage Model Summary} & & \\
\hline
\text{R-squared} & 0.902 & \text{Adj. R-squared} & 0.901 \\
\hline
& coef & std err & t-value & \texttt{P>|t|} \\
mon & 6580.0769 & 33.335 & 197.390 & 0.000 \\
tue & 6326.6840 & 33.276 & 190.130 & 0.000 \\
wed & 6020.3690 & 33.304 & 180.771 & 0.000 \\
thu & 6017.6003 & 33.153 & 181.509 & 0.000 \\
fri & 6064.1381 & 33.312 & 182.043 & 0.000 \\
sat & 3293.3294 & 39.696 & 82.964 & 0.000 \\
sun & 2329.8185 & 39.750 & 58.612 & 0.000 \\
holiday & -2594.7261 & 58.928 & -44.032 & 0.000 \\
shortage & -103.5165 & 54.318 & -1.906 & 0.057 \\
cov\_weekday& -316.7550 & 28.952 & -10.941 & 0.000 \\
cov\_sat & -2.1619 & 64.670 & -0.033 & 0.973 \\
cov\_sun & 29.0202 & 64.272 & 0.452 & 0.652 \\
sin\_1 & -53.2172 & 17.148 & -3.103 & 0.002 \\
cos\_1 & 59.3688 & 16.708 & 3.553 & 0.000 \\
sin\_2 & -86.3912 & 17.003 & -5.081 & 0.000 \\
cos\_2 & 20.3897 & 17.035 & 1.197 & 0.231 \\
sin\_3 & 79.5388 & 17.170 & 4.633 & 0.000 \\
cos\_3 & 40.4587 & 16.802 & 2.408 & 0.016 \\
sin\_4 & -13.3373 & 16.827 & -0.793 & 0.428 \\
cos\_4 & -10.7505 & 16.822 & -0.639 & 0.523 \\
sin\_5 & -24.8776 & 16.962 & -1.467 & 0.143 \\
cos\_5 & 12.4523 & 17.012 & 0.732 & 0.464 \\
sin\_6 & 1.0620 & 16.883 & 0.063 & 0.950 \\
cos\_6 & -12.7196 & 16.719 & -0.761 & 0.447 \\
sin\_7 & -4.3845 & 16.756 & -0.262 & 0.794 \\
cos\_7 & 19.6560 & 16.769 & 1.172 & 0.241 \\
\hline
\end{array}
Table 7. Summary of blood usage model
The signs of these estimates are consistent with a previous study [1], providing evidence that the model is well-identified.
3.3. Effects of Promotions
The Korean Red Cross employs promotional methods such as additional giveaways and sending blood donation request messages to address blood shortages. Among these methods, the additional giveaway promotion was conducted uniformly across all regions over a long period, rather than as a one-time event. For this reason, the effect of this promotion was primarily analyzed. Park (2018)[18] showed the impact of promotions on blood donors, but it was based on a survey and had limitations in that quantitative changes could not be measured.
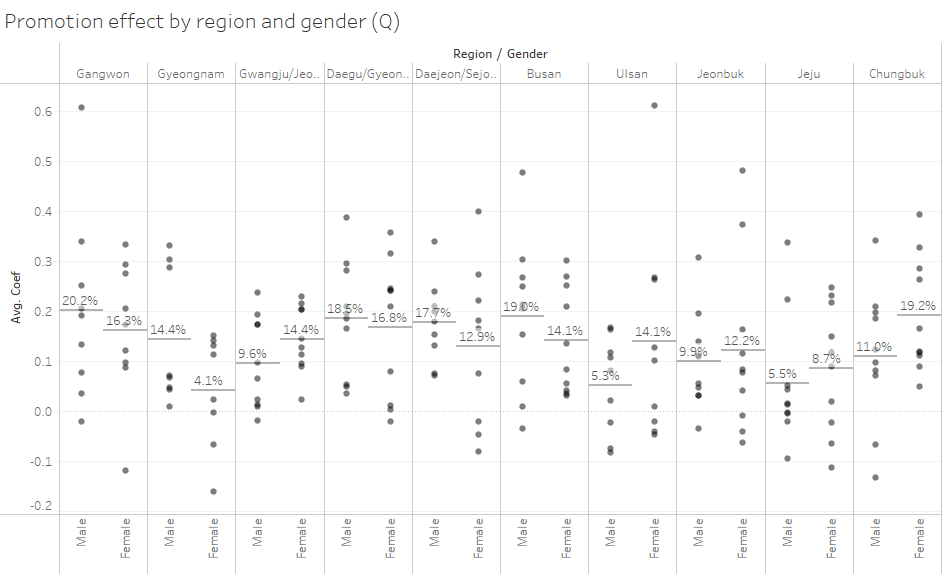
The effect of the additional giveaway promotion on the number of blood donors was confirmed by using promotion days as a dummy variable while controlling the exogenous factors considered earlier. To control the trend effect that could occur due to the clustering of promotion days (Figure 3), the entire period was divided into quarters, and the effect of promotions was measured within each quarter. To prevent outliers that could occur due to data imbalance within the quarter, only periods where the ratio of promotion days within the period ranged from 10% to 90% were used for the analysis. The Seoul, Gyeonggi, and Incheon regions were excluded from the analysis as the promotions were always carried out, making comparison impossible. Due to the nature of the dependent variable being affected by various social factors, the effect of promotions showed variance, but the mean of the distribution was estimated to be positive for all groups (Figure 4, Table 8).

In addition to the additional giveaway promotion, the Korean Red Cross conducts various special promotions. Special promotions include all promotions other than the additional giveaway promotion. As special promotions are conducted for short periods, trend effects cannot be eliminated by simply using dummy variables. Therefore, the net effect on the number of blood donors during special promotion periods was measured by comparing the number of donors during the promotion period with two weeks before and
\begin{array}{llr}
\hline
\textbf{Region} & \textbf{Gender} & \textbf{Average Promotion Effect} \\
\hline
\text{Gangwon}& \text{Male} & 20.2\% \\
& \text{Female} & 16.3\% \\
\hline
\text{Gyeongnam}& \text{Male} & 14.4\% \\
& \text{Female} & 4.1\% \\
\hline
\text{Gwangju/Jeonnam}& \text{Male} & 9.6\% \\
& \text{Female} & 14.4\% \\
\hline
\text{Daegu/Gyeongbuk}& \text{Male} & 18.5\% \\
& \text{Female} & 16.8\% \\
\hline
\text{Daejeon/Sejong/Chungnam}& \text{Male} & 17.7\% \\
& \text{Female} & 12.9\% \\
\hline
\text{Busan}& \text{Male} & 19.0\% \\
& \text{Female} & 14.1\% \\
\hline
\text{Ulsan}& \text{Male} & 5.3\% \\
& \text{Female} & 14.1\% \\
\hline
\text{Jeonbuk}& \text{Male} & 9.9\% \\
& \text{Female} & 12.2\% \\
\hline
\text{Jeju}& \text{Male} & 5.5\% \\
& \text{Female} & 8.7\% \\
\hline
\text{Chungbuk}& \text{Male} & 11.0\% \\
& \text{Female} & 19.2\% \\
\hline
\end{array}
Table 8. Gender and region-wise promotion effect
after the promotion. Among various special promotions, the sports viewing ticket give- away promotion showed a high performance in several regions: Gangwon (basketball), Gwangju/Jeonnam (baseball), Ulsan (baseball), and Jeju (soccer) Table 9.
\begin{array}{l|r|r}
\hline
\textbf{Region} & \textbf{Rank of the sports promotions} & \textbf{The number of special promotions} \\
\hline
\text{Gangwon} & 1st & 4\\
\text{Gyeongnam} & N/A & 9\\
\text{Gwangju/Jeonnam} & 1st, 3rd, 4th & 6\\
\text{Daegu/Gyeongbuk} & N/A & 7\\
\text{Daejeon/Sejong/} \\ \, \text{Chungnam} & N/A & 11\\
\text{Busan} & N/A & 6\\
\text{Ulsan} & 2nd & 4\\
\text{Jeonbuk} & N/A & 6\\
\text{Jeju} & 2nd & 7\\
\text{Chungbuk} & N/A & 7\\
\hline
\end{array}
Table 9. Performance of sports viewing ticket giveaway promotions by region
4. Conclusion
Previous studies had the limitation of not being able to quantitatively measure changes in blood stock during the COVID-19 pandemic and blood shortage situations. Furthermore, the effect of blood donation promotions on the number of blood donors in Korea has not been studied.
This study quantitatively analyzed changes in supply and usage during the pandemic and blood shortage situations, as well as the impact of various promotions, using exogenous variables, including time series variables, as control variables. According to the findings of this study, a stable blood supply can be achieved by improving the low promotion response in the Ulsan-si and Jeju-do regions and implementing sports viewing ticket giveaway promotions nationwide.
This study was conducted using short-term regional grouped data due to constraints in data collection. Given that blood donation centers within a region are not homogeneous and the characteristics of blood donors change over time, future research utilizing long-term individual blood donation center data and promotion data could significantly enhance the rigor and granularity of the analysis.
References
[1] Eunhee Kim. Impact of the covid-19 pandemic on blood donation. 2023.
[2] JunSeok Yang. The relationship between attitude on blood donation and altruism of blood donors in gwangju-jeonnam area. 2019.
[3] Jihye Yang. The factor of undergraduate student’s blood donation. 2013.
[4] Eui Yeong Shin. A study on the motivations of the committed blood donors. 2021.
[5] Dong Han Lee. Segmenting blood donors by motivations and strategies for retaining the donors in each segment. 2013.
[6] Shin Kim. A study on prediction of blood donation number using multiple linear regression analysis. 2015.
[7] Republic of Korea. Blood management act, 2023.
[8] Korean Red Cross Blood Services. 2022 annual statistical report on blood services, 2022.
[9] Korean Red Cross Blood Services. Daily data for the number of blood donors, blood usage, blood stock, and promotion dates, 2023.
[10] KoreaMeteorologicalAdministration.Automatedsynopticobservingsystem,2023.
[11] Korea Astronomy and Space Science Institute. Special day information, 2023.
[12] Peter C Young, Diego J Pedregal, and Wlodek Tych. Dynamic harmonic regression. Journal of forecasting, 18:369–394, 1999.
[13] H Akaike. Information theory as an extension of the maximum likelihood principle. A ́ in: Petrov, bn and csaki, f. In Second International Symposium on Information Theory. Akademiai Kiado, Budapest, pp. 276A ́281, 1973.
[14] Su mi Lee and Sungjo Hong. The effect of weather and season on pedestrian volume in urban space. Journal of the Korea Academia-Industrial cooperation Society, 20:56–65, 2019.
[15] Republic of Korea. Framework act on the management of disasters and safety, 2023.
[16] Hye Jin Bae, Byong Sun Ahn, Mi Ae Youn, and Don Young Park. Survey on blood donation recognition and korean red cross’ response during covid-19 pandemic. The Korean Journal of Blood Transfusion, 32:191–200, 2021.
[17] Statistics Korea. Sk telecom mobile data, 2020.
[18] Seongmin Park. Effects of blood donation events on the donors’ intentions of visit in ulsan. 2018.
Data Scientific Intuition that defines Good vs. Bad scientists
Data Scientific Intuition that defines Good vs. Bad scientists
Picture

Member for
2 months 1 weekReal name
Keith Lee
Position
Professor
입력
수정
Many amateur data scientists have little respect to math/stat behind all computational models
Math/stat contains the modelers' logic and intuition to real world data
Good data scientists are ones with excellent intuition
On SIAI's website, we can see most wannabe students go to MSc AI/Data Science program intro page and almost never visit MBA AI program pages. We have a shorter track for MSc that requires extensive pre-study, and much longer version that covers missing pre-studies. Over 90% of wannabes just take a quick scan on the shorter version and walk away. Less than 10% to the longer version, and almost nobody to the AI MBA.
We get that they are 'wannabe' data scientists with passion, motivation, and dream with self-confidence that they are the top 1%. But the reality is harsh. So far, less than 5% applicants have been able to pass the admission exam to MSc AI/Data Science's longer version. Almost never we have applicants who are ready to do the shorter one. Most, in fact, almost all students should compromise their dream and accept the reality. The fact that the admision exam is the first two courses of the AI MBA, lowest tier program, already bring students to senses that over a half of applicants usually disappear before and after the exam. Some students choose to retake the exam in the following year, but mostly end up with the same score. Then, they either criticize the school in very creative ways or walk away with frustrated faces. I am sorry for keeping such high integrity of the school.
Data Scientific Intuition that matters the most
The school focuses on two things in its education. First, we want students to understand the thought processes of data science modelers. Support Vector Machine (SVM), for example, reflects the idea that fitting can be more generalized if a separating hyperplane is bounded with inequalities, instead of fixed conditions. If one can understand that the hyperplane itself is already a generalization, it can be much easier to see through why SVM was introduced as an alternative to linear form fitting and what are the applicable cases in real life data science exercises. The very nature of this process is embedded in the school's motto, 'Rerum Cognoscere Causas' ((Felix, qui potuit rerum cognoscere causas - Wikipedia)), meaning a person pursuing the fundamental causes.
The second focus of the school is to help students where and how to apply data science tools to solve real life puzzles. We call this process as the building data scientific instuition. Often, math equations in the textbooks and code lines in one's program console screens do not have any meaning, unless it is combined in a way to solve a particular problem in a peculiar context with a specific object. Unlike many amateur data scientists' belief, coding libraries have not democratized data science to untrained students. In fact, the codes copied by the amateurs are evident examples of rookie failures that data science tools need must deeper background knowledge in statistics than simple code libraries.
Our admission exam is designed to weed out the dreamers or amateurs. After years of trials and errors, we have decided to give a full lecture of elementary math/stat course to all applicants so that we can not only offer them a fair chance but also give them a warning as realistic as our coursework. Previous schooling from other schools may help them, but the exam help us to see if one has potential to develop 'Rerum Cognoscere Causas' and data scientific intuition.
Intution does not come from hard study alone
When I first raised my voice for the importance of data scientific intution, I had had severe conflicts with amateur engineers. They thought copying one's code lines from a class (or a github page) and applying it to other places will make them as good as high paid data scientists. They thought these are nothing more than programming for websites, apps, and/or any other basic programming exercises. These amateurs never understand why you need to do 2nd-stage-least-square (2SLS) regression to remove measurement error effects for a particular data set in a specific time range, just as an example. They just load data from SQL server, add it to code library, and change input variables, time ranges, and computer resources, hoping that one combination out of many can help them to find what their bosses want (or what they can claim they did something cool). Without understanding the nature of data process, which we call 'data generating process' (DGP), their trials and errors are nothing more than higher correlation hunting like untrained sociologists do in their junk researches.
Instead of blaming one code library worse performing than other ones, true data scientists look for embedded DGP and try to build a model following intuitive logic. Every step of the model requires concreate arguments reflecting how the data was constructed and sometimes require data cleaning by variable re-structuring, carving out endogeneity with 2SLS, and/or countless model revisions.
It has been witnessed by years of education that we can help students to memorize all the necessary steps for each textbook case, but not that many students were able to extend the understanding to ones own research. In fact, the potential is well visible in the admission exam or in the early stage of the coursework. Promising students always ask why and what if. Why SVM's functional shape has $1/C$ which may limit the range of $C$ in his/her model, and what if his/her data sets with zero truncation ends up with close to 0 separating hyperplane? Once the student can see how to match equations with real cases, they can upgrade imaginative thought processes to model building logic. For other students, I am sorry but I cannot recall successful students without that ability. High grades in simple memory tests can convince us that they study hard, but lack of intuition make them no better than a textbook. With the experience, we design all our exams to measure how intuitive students are.

Intuition that frees a data scientist
In my Machine Learning class for tree models, I always emphasize that a variable with multiple disconnected effective ranges in trees has a different spanned space from linear/non-linear regressions. One variable that is important in a tree space, for example, may not display strong tendency in linear vector spaces. A drug that is only effective to certain age/gender groups (say 5~15, 60~ for male, 20~45 female) can be a good example. Linear regression hardly will capture the same efffective range. After the class, most students understand that relying on Variable Importances of tree models may conflict with p-value type variable selections in regression-based models. But only students with intuition find a way to combine both models that they find the effective range of variables from the tree and redesign the regression model with 0/1 signal variables to separate the effective range.
The extend of these types of thought process is hardly visible from ordinary and disqualified students. Ordinary ones may have capacity to discern what is good, but they often have hard time to apply new findings to one's own. Disqualified students do not even see why that was a neat trick to the better exploitation of DGP.
What's surprising is that previous math/stat education mattered the least. It was more about how logical they are, how hard-working they are, and how intuitive they are. Many students come with the first two, but hardly the third. We help them to build the third muscle, while strenghtening the first. (No one but you can help the second.)
The re-trying students ending up with the same grades in the admission exam are largely because they fail to embody the intuition. It may take years to develop the third muscle. Some students are smart enough to see the value of intuition almost right away. Others may never find that. For failing students, as much as we feel sorry for them, we think that their undergraduate education did not help them to build the muscle, and they were unable to build it by themselves.
The less chanllenging tier programs are designed in a way to help the unlucky ones, if they want to make up the missing pieces from their undergraduate coursework. Blue pills only make you live in fake reality. We just hope our red pill to help you find the bitter but rewarding reality.
Picture
Member for
2 months 1 weekReal name
Keith Lee
Position
Professor







AI Pessimism, just another correction of exorbitant optimism
AI Pessimism, just another correction of exorbitant optimism
입력
수정
AI talks turned the table and become more pessimistic
It is just another correction of exorbitant optimism and realisation of AI's current capabilities
AI can only help us to replace jobs in low noise data
Jobs needing to find new patterns and from high noise data industry, mostly paid more, will not be replaceable by current AI
There have been pessimistic talks about the future of AI recently that have created sudden drops in BigTech firms' stock prices. In all of a sudden, all pessimistic talks from Investors, experts, and academics in reputed institutions are re-visited and re-evaluated. They claim that ROI (Return on Investment) for AI is too low, AI products are too over-priced, and economic impact by AI is minimal. In fact, many of us have raised our voices for years with the exactly same warnings. 'AI is not a magic wand'. 'It is just correlation but not causality / intelligence'. 'Don't be overly enthusiastic about what a simple automation algorithm can do'.
As an institution with AI in our name, we often receive emails from a bunch of 'dreamers' that they wonder if we can make a predictive algorithm that can foretell stock price movements with 99.99% accuracy. If we could do that, why do you think we would share the algorithm with you? We should probably keep it for secret and make billions of dollars just for ourselves. As much as the famous expression by Milton Friedman, a Nobel economist, there is no such thing as a free lunch. If we have a perfect predictability and it is widely public, then the prediction is no longer a prediction. If everyone knows the stock A's price goes up, then everyone would buy the stock A, until it reaches to the predicted value. Knowing that, the price will jump to the predicted value, almost instantly. In other words, the future becomes today, and no one gets benefited.

AI = God? AI = A machine for pattern matching
A lot of enthusiasts have exorbitant optimism that AI can overwhelm human cognitivie capacity and soon become god-like feature. Well, the current forms of AI, be it Machine Learning, Deep Learning, and Generative AI, are no more than a machine for pattern matching. You touch a hot pot, you get a burn. It is painful experience, but you learn that you should not touch when it is hot. The worse the pain, the more careful you become. Hopefully it does not make your skin irrecoverable. The exact same pattern works for what they call AI. If you apply the learning processes dynamically, that's where Generative AI comes. The system is constantly adding more patterns into the database.
Though the extensive size of patterns does have great potential, it does not mean that the machine has cognitive capacity to understand the pattern's causality and/or to find new breakthrough patterns from list of patterns in the database. As long as it is nothing more than a pattern matching system, it never will.
To give you an example, can it be used what words you are expected to answer in a class that has been repeated for thousand times? Definitely. Then, can you use the same machine to predict the stock price? Aren't the stock market repeating the same behavior over a century? Well, unfortunately it is not, thus you can't be benefited by the same machine for financial investments.
Two types of data - Low noise vs. High noise
On and near the Wall Street, you can sometimes meet an excessively confident hedge fund manager with claims on near perfect foresight for financial market movements. Some of them have outstanding track records, and surprisingly persuasive. In New York Times archive back in 1940s, or even as early as 1910s, you can see people with similar claims were eventually sued by investors, arrested due to false claims, and/or just disappeared from the street within a few years. If they were that good, why then they lost money and got sued/arrested?
There are two types of data. One set of data that you can see from machine (or highly controlled environment) is called 'Low-noise' data. It has high predictability. Even in cases where embedded patterns are invisible by bare eyes, you either need more analytic brain or a machine to test all possibilities within the possible sets. For the game of Go, the brain was Se-dol Lee and the machine was Alpha-Go. The game needs to test 19x19 possible sets with around 300 possible steps. Even if your brain is not as good as Se-dol Lee, as long as your computer can find the winning patterns, you can win. This is what has been witnessed.
The other set of data comes from largely uncontrolled environment. There potentially is a pattern, but it is not the single impetus that drives every motion of the space. There are thousands, if not millions, of patterns that the driver is not observable. This is where randomness is needed for modeling, and it is unfortunately impossible to predict accurate move, because the driver is not observable. We call this set of data 'High-noise'. The stock market is the very example of such. There are millions of unknown, unexpectable, and at least unmeasurable influences that disable any analyst or machine to predict with accuracy level upto 100%. This is why financial models are not researched for predictability but used only to backtest financial derivatives for reasonable pricing.
Natural language process (NLP) is one example of low noise. Our language follows a certain set of rules (or patterns), which are called grammar. Unless you are uneducated or intentionally out of grammar (or make mistakes), people generally follow grammar. Weather is mostly low noise, but it has high noise components. Sometimes typhoons are unpredictable, or less predictable. Stock market? Be my guest. There have been 4 Nobel Prizes given to financial economists by year 2023, and all of them are based on the belief that stock markets follow random processes, be it Gaussian, Poisson, and/or any other unknown random distributions. (Just in case, if a process follows any known distribution, that means it is probabilistic, which means it is random.)

Potential benefits of AI
We as an institution hardly believe current forms of AI will make any significant changes in businesses and our life in short term. The best we can expect is automation of mundane tasks. Like laundary machine in early 20th century. ChatGPT already has shown us a path. Soon, CS operators will largely be replaced by LLM based chatbots. US companies actively outsourced the function from India for the past a few decades, thanks to cheaper international connectivity via internet. It will still remain, but human actions will be needed way less than before. In fact, we already get machine generated answers from a number of international services. If we complain about a program's malfunction on a WordPress plugin, for instance, established services email us machine answers first. For a few cases, it actually is enough. The practice will become more popular to less-established services as it becomes easier and cheaper to implement.
Teamed up with EduTimes, we also are working on a research to replace 'Copy Boys/Girls'. Journalists that we know from large news magazines are not always running on the street to find new and fascinating stories. In fact, most of them read other newspapers and rewrite the contents as if they were the original sources. Although it is not an important job, it is still needed for the newspaper to run. They need to keep up the current events, accoring to the EduTimes journalists from other renouned newspapers. The copy team is usually paid the least and seen a death sentence as a journalist. What makes the job more sympathetic on top of the least respect, it will soon be replaced by LLM based copywriters.
In fact, any job that generates patterned contents without much of cognitivie functions will gradually be replaced.
What about automotive driving? Is it a low-noise pattern job or a high-noise complicated cognitive job? Well, although Elon Musk claims high possibility of Lv. 4 auto-driving within next a few years, we don't believe so. None of us at GIAI have seen any game theorists have solved multi-agent ($n$>2) Bayesian belief game with imperfect information and unknown agent types by computer so that the automotive driving algorithm can predict what other drivers on the road will do. Without the right prediction of others on the fast moving vehicles, it is hard to tell if your AI will help you successfully avoid other crazy drivers. The driving job for those eventful cases needs 'instinct', which requires another set of bodily function different from cognitive intelligence. The best that the current algorithm can do is to tighten it up to perfection for a single car, which already needs to go over a lot of mathematical, mechanical, organisational, legal, and commercial (and many more) challenges.
Don't they know all that? Aren't the Wall Street investors self-confident, egocentric, but ultra smart that they already know all the limitations of AI? We believe so. At least we hope so. Then, why do they pay attention to the discontentful pessimism now, and create heavy drops in tech stock prices?
Guess the Wall Street hates to see Silicon Valley to be paid too much. American East often think the West too unrealistic and floating in the air. OpenAI's next round funding may surprise us in a totally opposite direction.
MSc AI/Data Science vs. Boot Camp for AI
MSc AI/Data Science vs. Boot Camp for AI
입력
수정
Boot camp is for software programming without mathematical training
MSc is a track for PhD, with in-depth scientific research written in the language of math and stat
We respect programmers, but our works are significantly varying
Due to the fact that we are running SIAI, an higher educational institution for AI/Data Science, we often have questions about the difference between Boot Camps for AI and MSc programmes. The shortest answer is the difference in Math requirements. Masters track is for people looking for academic training so that one can read academic papers in that subject. With PhD in the topic, we expect the student to be able to lead a research. From Boot Camp, sorry to be a little aggressive here, but we only expect a 'Coding Monkey'.
We are aware that many countries are shallow in AI/Data Science that they want employees only to be able to best use of Open AI's and AWS's libraries by Rest API. For that, boot camp should be enough, unless the boot camp teacher does not know how to do so. There are nearly infinite amount of contents for how to use Rest API for your software, regardless of your backend platform, be it an easy script languages like Python or tough functional ones like OCaml. Difficulties are not always indicators of determinants in challenges, and we, as data scientists at GIAI, care less about what language you use. What's important is how flexible your thinking for mathematically contained modeling.
Boot camp for software programing, MSc for scientific training
Unfortunately, unless you are lucky enough to be born as smart as Mr. Ramanujan, you cannot learn math modeling skills from a bunch of blogs. Programming, however, has infinitely many proven records of excellent programmers without school traninng. Elon Musk is just one example. He did Economics and Physics in his undergrad at U Penn, and he only stayed one day in the mechanical engineering PhD program at Stanford University. Programming is nothing more than a logic, but math needs too many building blocks to understand the language.
When we first build SIAI, we had quite a lengthy discussion for weeks. Keith was firm that we should stick to mathematical aspects of AI/Data Science. (which doesn't mean we should only teach math, just to avoid any misunderstanding.) Mc wanted two tier tracks for math and coding. We later found that with coding, it is unlikely that we can have the school accreditted by official parties, so we end up with Keith's idea. Besides, we have seen too many Boot Camps around the world that we do not believe we can be competitive in that regard.
The founding motto of the school is 'Rerum Cognoscere Causaus', meaning 'the real cause of things'. With mathematical tools, we were sure that we can teach what are the reason behind a computational model was first introduced. Indeed, Keith has done so well in his Scientific Programming that most students no longer bound to media brainwashing that Neural Network is the most superior model.

Scientists do our own stuff
If you just go through Boot Camps for coding, chances are that you can learn the limitations of Neural Network just by endless trials and errors, if not somebody's Medium posts and Reddit comments. In other words, without the proper math training, it is unlikely one can understand how the computational logics of each model are built, which makes us to aloof from all programmers without necessary math training.
The very idea comes from multiple rounds of uneasy exposures to software engineers without a shred of understanding in modeling side of AI. They usually claim that Neural Network is proven to be the best model, and they do not need any other model knowledge. And all they have to do is to run and test it. Researchers at GIAI are trained scientists, and we mostly can guess what will happen just by looking at equations. And, most importantly, we are well aware that NN is the best model only for certain tasks.
They kept claim that they were like us, and some of them wanted to build a formal assocation with SIAI (and later GIAI). It's hard for us to work with them, if they keep that attitude. These days, whenever we are approached by third parties, if they want to be at equals with us, we ask them to show us math training levels. Please make no mistake that we respect them as software engineers, but we do not respect them as scientists.
Guess aforementioned story and internal discomfort tells you the difference between software engineers and data/research scientists, let alone tools that we rely on.
We screen out students by admission exams in math/stat
With the experience, Keith initiated two admission exams for our MSc AI/Data Science programmes. At the very beginning, we thought there will be plenty of qualifying students, so we used final year undergrad materials. There was a disaster. We gave them two months of dedicated training. Provided similar exams and solved each one of them with extra detail. But, only 2 out of 30 students were able to get grades good enough to be admitted.
We lowered the level down to European 2nd year (perhaps American 3rd year), and the outcome wasn't that different. Students were barely able to grasp superficial concepts of key math/stat. This is why we were kinda forced to create an MBA program that covers European 2nd year teaching materials with ample amount of business application cases. With that, students survive, but answer keys in their final exam tell us that many of them belong to coding Boot Camps, not SIAI.
From year 2025 and onwards, we will have one admission exam for MSc AI/Data Science (2 year) in March, after 2 months pre-training in Jan and Feb. The exam materials will be 2nd year undergrad level. If a student passes, we offer an exam with one notch up in June, again after 2 months pre-training in Apr and May. This will give them MSc AI/Data Science (1 year) admission.
Students who failed the 2-year track admission, we offer them MBA AI program admission, which covers some part of the 2-year track courses. If they think they are ready, then in the following year, they can take the admission exam again. After a year of various courework, some students have shown better performance, based on our statistics, but not by much. It seemed like the brain has its limit that they cannot go above.
Precisely by the same reason, we are reasonably sure that not that many applicants will be able to come to 2-year track, and almost no one for the 1-year track. More details are available from below link:
Why Companies cannot keep the top-tier data scientists / Research Scientists?
Why Companies cannot keep the top-tier data scientists / Research Scientists?
Picture
Member for
2 months 1 weekReal name
Keith Lee
Position
Professor
입력
수정
Top brains in AI/Data Science are driven to challenging jobs like modeling
Seldom a 2nd-tier company, with countless malpractices, can meet the expectations
Even with $$$, still they soon are forced out of AI game
A few years ago, a large Asian conglomerate acquired a Silicon Valley's start-up just off an early Series A funding. Let's say it is start-up $\alpha$. The M&A team leader later told me that the acquisition was mostly to hire the data scientist in the early stage start-up, but the guy left $\alpha$ on the day the M&A deal was announced.
I had an occation to sit down with the data scientist a few months later, and asked him why. He tried to avoide the conversation, but it was clear that the changing circumstances definitely were not within his expectation. Unlike other bunch of junior data scientists in Silicon Valley's large firms, he did signal me his grad school training in math and stat that I had a pleasant half an hour talk about models. He was mal-treated in large firms that he was given to run SQL queries and build Tableau-based graphes, like other juniors. His PhD training was useless in large firms, so he had decided to be a founding member of $\alpha$ that he can build models and test them with live data. The Asian acquirer with bureaucratic HR system wanted him to give up his agenda and to transplant the Silicon Valley large firm's junior data scientist training system to the acquirer firm.

Brains go for brains
Given tons of other available positions, he didn't waste his time. Personall,y I also have lost some months of my life for mere SQL queries and fancy graphes. Well, some people may still go for 'data scientist' title, but I am my own man. So was the data scientist from $\alpha$.
These days, Silicon Valley firms call the modelers as 'research scientists', or simliar names. There also are positions called 'machine learning engineers' whose jobs somewhat related to 'research scientists', but may disinclude mathematical modeling parts and way more software engineering in it. The title 'Data Scientists' are now given to jobs that were used to be called 'SQL monkeys'. As the old nickname suggests, not that many trained scientists would love to do the job, even with competitive salary package.
What companies have to understand is that we, research scientists, are not trained for SQL and Tableau, but mathematical modeling. It's like a hard-trained sushi cook(将太の寿司, shota no sushi) is given to make street food like Chinese noodle.
Let me give you an example in real corporate world. Let's say a semi-conductor company, $\beta$ wants to build a test model for a wafer / subsctrate. What I often hear from those companeis are that they build a CNN model that reads the wafer's image and match it with pre-labeled 0/1 for error detection. In fact, similar practices have been widely adapted practice among all Neural Network maniacs. I am not saying it does not work. It works. But then, what would you do, if the pre-label was done poorly? Say, the 0/1 entries were like over 10,000 and hardly any body double checked the accruracy. Can you rely on that CNN-based model? In addition to that, the model probably require enourmous amount of computational costs to build, let alone test and operating it daily.
Wrong practice that drives out brain
Instead of the costly and less scientific option, we can always build a model that captures data's generated process(DGP). The wafer is composed of $n \times k$ entries, and issues emerge when $n \times 1$ or $1 \times k$ entries go wrong altogether. Given the domain knowledge, one can build a model with cross-products between entries in the same row/column. If it is continuously 1 (assume 1 for error), then it can easily be identified as a defect case.
Cost of building a model like that? It just needs your brain. There is a good chance that you don't even need a dedicated graphics card for that calculation. Maintenance costs are also incomparably smaller than the CNN version. The concept of computational cst is something that you were supposed to learn in any scientific programming classes at school.
For companies sticking to the expensive CNN options, I always can spot followings:
- The management has little to no sense of 'computational cost'
- The manaement cannnot discern 'research scientists' and 'machine learning engineers'
- The company is full of engineers without the sense of mathematical modeling
If you want to grow up as a 'research scientist', just like the guy at $\alpha$, then run. If you are smart enough, you must have already run, like the guy at $\alpha$. After all, this is why many 2nd-tier firms end up with CNN maniacs like $\beta$. Most 2nd-tier firms are unlucky that they cannot keep research scientists due to lack of knowledge and experience. Those companies have to spend years of time and millions of wasted dollars to find that they were so long. By the time that they come to senses, it is mostly already way too late. If you are good enough, don't waste your time on a sinking ship. The management needs so-called cold-turkey type shock treatment as a solution. In fact, there was a start-up that I stayed only for a week, which lost at least one data scientist in everyweek. The company went to bankrupt in 2 years.
What to do and not to do
At SIAI, I place Scientific Programming right after elementary math/stat training. Students see that each calculation method is an invention to overcome earlier available options' limitations but simultanesouly the modification bounds the new tactic in another directions. Neural Networks are just one of the many kinds. Even with the eye-opening experience, some students still remain NN maniacs, and they flunk in Machine Learning and Deep Learning classes. Those students believe that there must exist a grand model that is univerally superior to all other models. I wish the world is that simple, but my ML and DL courses break the very belief. Those who are awaken, usually become excellent data/research scientists. Many of them come back to me that they were able to minimize computational costs by 90% just by replacing blindly implemented Neural Network models.
Once they see that dramatic cost reduction, at least some people understand that the earlier practice was wrong. The smarty student may not be happy to suffer from poor management and NN maniacs for long. Just like the guy at $\alpha$, it is always easier to change your job than fighting to change your incapable management. Managers moving fast maybe able to withhold the smarty. If not, you are just like the $\beta$. You invest a big chunk of money for an M&A just to hire a smarty, but the smarty disappears.
So, if you want to keep the smarty? Your solution is dead simple. Test math/stat training levels in scientific programming. You will save tons of $$$ in graphic card purchase.
Picture
Member for
2 months 1 weekReal name
Keith Lee
Position
Professor