The Managerial Data Science Association (MDSA) will be incorporated under the Global Institute of Artificial Intelligence (GIAI).
On the 1st, MDSA (Chairman Hoyong Choi, Professor of Biotechnology Management at KAIST) confirmed its incorporation into GIAI based on the decision of the New Year’s general meeting. As an issue that has been prepared since its establishment in March of last year, MDSA plans to conduct various AI/data science activities in Korea by utilizing GIAI’s global network, research capabilities, and educational capabilities.
GIAI is a group of AI researchers established in Europe in 2022, and its members include the Swiss Institute of Artificial Intelligence (SIAI), the American education magazine EduTimes, and MBA Rankings. SIAI is an institution where SIAI Professor Keith Lee, one of the founders of MDSA, teaches AI/Data Science. GIAI’s research institute (GIAI R&D) is operated based on a network of researchers from all over the world. Research papers and contributions from AI researchers are made public on the affiliated research institute’s webpage.
Meanwhile, MDSA is changing its website address with this incorporation. The previous address will be discarded and the homepage will be changed to the structure below.
Why market interest rates fall every day while the U.S. Federal Reserve waits and why Bitcoin prices continue to rise
Picture
Member for
2 months 1 week
Real name
Keith Lee
Position
Professor
입력
수정
When an expectation for future is shared, market reflects it immediately US Fed hints to lower interest rates in March, which is already reflected in prices Bitcoin prices also rely on people's belief on speculative demands
The US Fed determines the base interest rate approximately once every 1.5 months, eight times a year. There is no reason for the market to immediately follow the next day when the Federal Reserve sets an interest rate, and in fact, changing the base rate or target interest rate does not mean that it can change the market the next day, but it is a method of controlling the amount of money supplied to general banks, It is common for interest rates to be substantially adjusted within one to two weeks by appropriately utilizing methods such as controlling bond sales volume.
The system in which most central banks around the world set base interest rates in a similar way and the market moves accordingly has been maintained steadily since the early 1980s. The only difference from before was that the money supply was the target at that time, and now the interest rate is the target. As experience with appropriate market intervention accumulates, the central bank also learns how to deal with the market, and the market also changes according to the central bank's control. The experience of becoming familiar with interpreting expressions goes back at least 40 years, going back as far as the Great Depression in the United States in 1929.
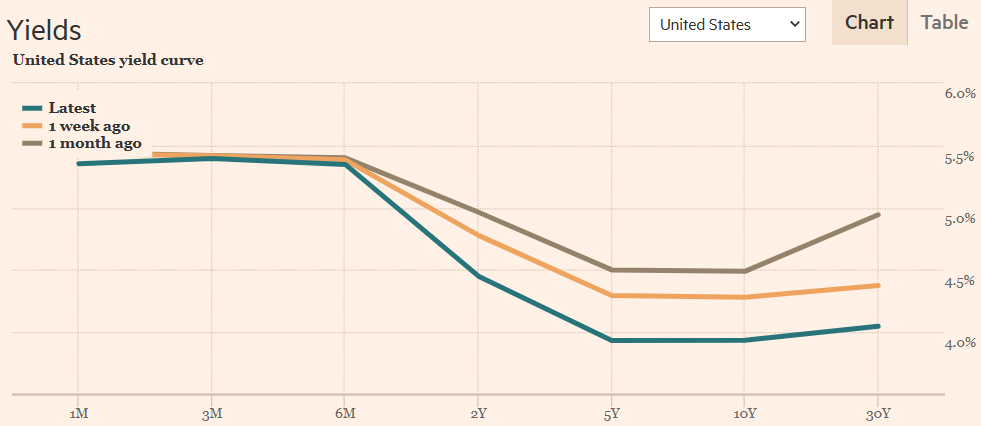
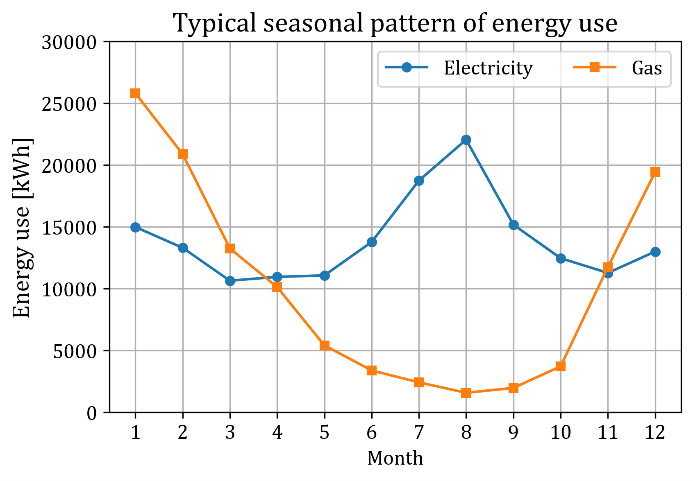
However, the Federal Reserve declared that it is not time to lower interest rates yet and that it will wait until next year, but interest rates at commercial banks are lowering day after day. I briefly looked at the changes in US interest rates in the Financial Times, and saw that long-term bond interest rates were falling day by day.
Why is the market interest rate lowering while the Federal Reserve remains silent?
Realization of expectations
Let’s say that in one month, the interest rate falls 1% from now. Unless you need to get a loan tomorrow, you will have to wait a month before going to the bank. No, these days, you can send documents through apps and non-face-to-face loans are also active, so you won't have to open your banking app and open the loan menu for a month.
From the perspective of a bank that needs to make a lot of loans to secure profitability, if the number of such customers increases, it will have to suck its fingers for a month. What happens if there is a rumor that interest rates will fall further in two months? You may have to suck only your fingers for two months.
Let’s put ourselves in the position of a bank branch manager. In any case, it is expected that the central bank will lower interest rates in a month, and everyone in the market knows that, so it is not a post-reflection where interest rate adjustments are hastily made in the market after the central bank announcement, but everyone is not interested in the announcement date. If it is certain that it will be reflected in advance, there will be predictions that the market interest rate will be adjusted sooner than one month. Since you have worked your way up to the branch manager level, you clearly know how the industry is going, so you can probably expect to receive a call from the head office in two weeks to lower the interest rate and ask for loans and deposits. However, the only time a loan is issued on the same day after receiving the loan documents is when the president's closest aide comes and makes a loud noise. Usually, more than a week is spent on review. There are many cases where it takes 2 weeks or 1 month.
Now, as a branch manager with 20+ years of banking experience who knows all of this, what choice would you make if it was very certain that the central bank would lower interest rates in one month? You have to build up a track record by giving out a lot of loans to be able to look beyond branch manager, right? We have to win the competition with other branches, right?
Probably a month ago, he issued an (unofficial) work order to his branch staff to inform customers that loan screening would be done with lower interest rates, and while having lunch with wealthy people nearby, he said that his branch would provide loans with lower interest rates, and talked to good people around him about it. We will introduce you to commercial buildings. They say that you can make money if you buy something before someone else does.
When everyone has the same expectation, it is reflected right now
When I was studying for my doctorate in Boston, there was so much snow in early January that all classes were cancelled. Then, in February, when school started late, a professor emailed us in advance to tell us to clear our schedules, saying that classes would be held on from Monday to Friday.
I walked into class on the first day (Monday), and as the classmates were joking that we would see each other every day that week, and the professor came to the classroom. And then to us
I'm planning to take a 'Surprise quiz' this week.
We were thinking that the eccentric professor was teasing us with strange things again. The professor asked again when they would take the surprise quiz. For a moment, my mind raced: When will be the exam? (The answer is in the last line of the explanation below.)
If there is no Surprise Quiz by Thursday, Friday becomes the day to take the Quiz. It's no longer a surprise. So Friday cannot be the day to take the Surprise quiz.
What happens if there is no surprise quiz by Wednesday? Since Friday is not necessarily the day to take the Surprise quiz, the remaining day is Thursday. But if Friday is excluded and only Thursday remains, isn't Thursday also a Surprise? So it's not Thursday?
So what happens if there is no Surprise quiz by Tuesday? As you can probably guess by now, Friday, Thursday, Wednesday, and Tuesday do not all meet the conditions for Surprise by this logic. What about the remaining days?
It was Monday, right now, when the professor spoke.
As explained above, we are told to take out a piece of paper, write our names, write an answer that logically explains when the Surprise quiz will be, and submit it. I had no idea, but then I suddenly realized that the answer I had to submit now was the answer to the Surprise quiz, so I wrote the answer above and submitted it.
The above example is a good explanation of why the stock price of a company jumps right now if you predict that the stock price of that company will rise fivefold in one month. In reality, the stock market determines stock prices based on the company's profitability over two or three quarters, not on its profitability today. If the company is expected to grow explosively during the second or third quarter, this will be reflected in advance today or tomorrow. The reason it is delayed until tomorrow is due to regulations such as daily price limits and the time it takes to spread information. Just as there is a gap between students who can submit answers to test questions right away and students who need to hear explanations from their friends after the test, the more advanced information is, the slower its spread may be.
Everyone knows this, so why does the Fed say no?
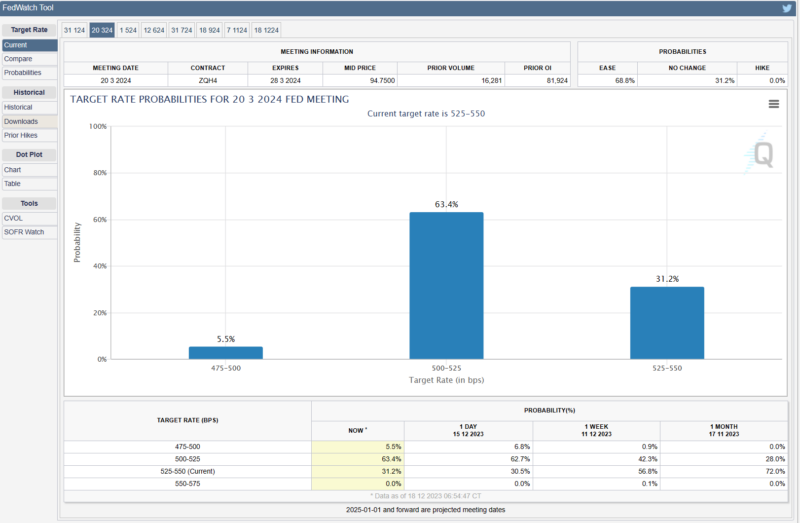
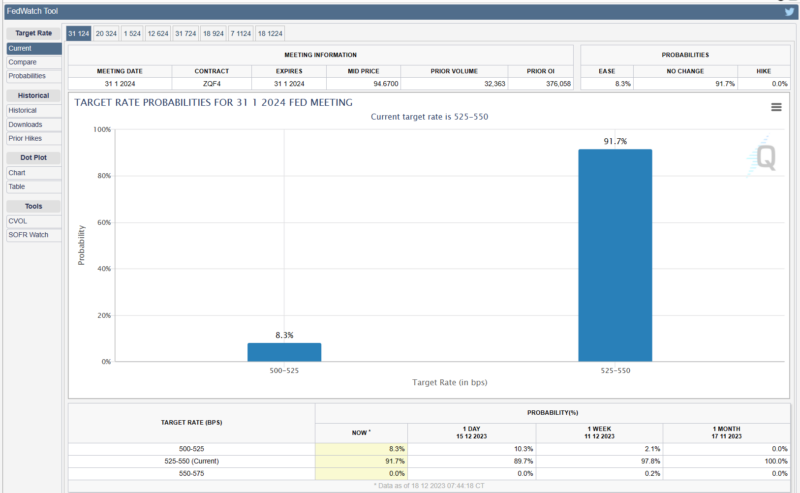
Until last October and November, at least some people disagreed with the claim that an interest rate cut would be visible in March of next year. As there is growing confidence that the US will enter a recession in December, there is now talk of lowering interest rates at a meeting on January 31st rather than in March. Wall Street financial experts voted for a possibility that was close to 10%, which was only 0% just a month ago. Meanwhile, Federal Reserve Chairman Powell continues to evade his comments, saying that he cannot yet definitively say that he will lower interest rates. We all know that even if we don't know about January, we are sure about March, but he has much more information than us, and there are countless economics doctors under him who will research and submit reports, so why does he react with such ignorance? Should I do it?
Let's look at another example similar to the Surprise quiz above.
When the professor entered the first class of the semester, he announced that the grade for this class would be determined by one final exam, and that he planned to make it extremely difficult. Many students who were trying to earn credits day by day will probably escape during the course adjustment period. The remaining students have a lot of complaints, but they still persevere and listen carefully to the class, and later on, because the content is too difficult, they may form a study group. Let's imagine that it's right before the final exam and your professor knows that you studied so hard.
The professor's original goal was for students to study hard, not to harass them by giving difficult test questions. Writing tests is a hassle, and grading them is even more bothersome. If you have faith that the remaining students will do well since you kicked out the students who tried to eat raw, it may be okay to just give all the remaining students an A. Because everyone must have studied hard.
When I entered the exam room,
No exam. You all have As. Merry Christmas and Happy New Year!
Isn’t it written like this?
From the students' perspective, they may feel like they are being made fun of and that they feel helpless. However, from the professor’s perspective, this decision was the best choice for him.
Students who tried to eat it raw were kicked out.
The remaining students studied hard.
Reduced the hassle of writing test questions
You don't have to grade
When entering your grade, you only need to enter the A value.
No more students complaining about grading.
The above example is called 'Time Inconsistency' in game theory, and is often used as a general example of a case where the optimal choice varies depending on time. Of course, if we continue to use the same strategy, 'students who want to eat raw' will flock to register for the next semester. So, in the next semester, you must take the exam and become an 'F bomber' who gives a large number of F grades. At a minimum, students must use the Time Inconsistency strategy at unpredictable intervals for the strategy to be effective.
The same logic can be applied to Federal Reserve Chairman Powell. Although interest rates are scheduled to be lowered in March or January next year, if they remain silent until the end, it could reflect their will to prevent overheating of the economy by raising interest rates. Then, if interest rates are suddenly lowered, an economic recession can be avoided.
Those who do macroeconomics summarize this with the expressions ‘discretion’ and ‘rules.’ 'Discretion' refers to government policy that responds in accordance with market conditions, and 'rules' refers to a decision-making structure that ignores market conditions and moves in accordance with standard values. Generally, a structure that promotes 'rules' on the outside and uses 'discretion' behind the scenes. has worked like a market rule for the past 40 years.
Because of this accumulated experience, sometimes the central banker sticks to the 'rules' until the end and devises a defensive strategy so that the market does not expect 'discretion', and sometimes he comes up with a strategy to respond faster than the market expects. These are all choices made to show that market expectations are not unconditionally followed by using Time Inconsistency or vice versa.
Examples
Such cases of surprise quizzes and no exams can often be found around us.
Although products like Bitcoin are nothing more than 'digital pieces' with no actual value, there are some people who have a firm belief that it will become a new currency replacing the central government's currency, and some who are not sure about currency and just buy it because the price goes up. Prices fluctuate repeatedly due to the buying and selling actions of the (overwhelming) majority of like-minded investors. The logic of a surprise quiz is hidden in the behavior of buying because it seems like it will go up, and in the attitude of never admitting it and insisting on the value until the end, even though you know in your heart that it is not actually worth it, there is a central bank-style strategy using no exam hidden. .
The same goes for the behavior of 'Mabari', a so-called securities broker who raises the stock price of theme stocks by creating wind, and the sales pitch of academies that say you can become an AI expert with a salary in the hundreds of millions of dollars by simply obtaining a code is also the same. They all cleverly exploit the asymmetry of information, package tomorrow's uncertain value as if it is great, and sell today's products by inflating their value.
Although it is not necessarily a case of fraud, cases where value is reflected in advance are common around us. If the price of an apartment in Gangnam looks like it will rise, it rises overnight, and if it looks like it will fall, it moves several hundred million won in a single morning. This is because the market does not wait and immediately reflects changed information.
Of course, this pre-reflected information may not always be correct. You will often hear the expression ‘over-shooting’, which refers to a situation where the market overreacts and stock prices rise excessively, or real estate prices fall excessively. There may be many reasons, but it happens because people who follow what others say and brainwash their brains do not accurately reflect the value of information. Generally, in the stock market, if there is a large rise for one or two days, the stock price tends to fall slightly the next day, which is a clear example of 'overshooting'.
Can you guess when the interest rate will drop?
Whenever I bring up this topic, the person who was dozing off wakes up at the end and asks, 'Please tell me when the interest rate will go down.' He says he can't follow complicated logic, he just needs to know when the interest rate goes down.
If you have been following the story above, you will be predicting that interest rate adjustments will continue to occur in the market between the Christmas and New Year holidays before the central bank lowers interest rates. It is unclear whether the decision to lower interest rates will be made on January 31 or March 20 next year. Because it’s their heart. Economic indicators are just numbers, and ultimately, they are values that only move when people make decisions that risk their future reputations, but I can't get into their minds.
However, since they also have the rest of their lives, they will try to make rational decisions, and those who are smart enough to solve the Surprise quiz on the spot will adjust their expectations the fastest and become market readers, and those who solve the problem will become the market readers. People who have heard of it and know about it will miss the opportunity due to the information time lag, and people who ask 'just tell me when it will arrive' will only respond belatedly after the whole incident has occurred. While you're sending emails asking who's right, you'll find out later that the market correction is over. To paraphrase, it is already coming down. The 30-year maturity bond interest rate, which was close to 5.0% a month ago, fell to 4.0%?
The process of turning web novels into webtoons and data science
Picture
Member for
2 months 1 week
Real name
Keith Lee
Position
Professor
입력
수정
Web novel to Webtoon conversion is not only based on 'profitability' If the novel author is endowed with money or bargaining power, 'Webtoonization' may be nothing more than a marketting tool for the web novel. Data science modeling based on market variables unable to grab such cases
A student in SIAI's MBA AI/BigData progam, struggling with her thesis, chose her topic as the condition for turning a web novel into a webtoon. In general, people would simply think that if the number of views is high and the sales volume of the web novel is large, a follow-on contract with a webtoon studio will be much easier. She brought in a few reference data science papers, but they only looked into publicly available information. What if the conversion was the choice of the web novel author? What if the author just wanted to spend more marketing budget by adding webtoon in his line-up?
Literature mostly runs hierarchical structures during 'deep learning' and use 'SVM', a task that simply relies on computer calculations, and calculate the number of all cases provided by the Python library. Sorry to put it this way, but such calculations are nothing more than a waste of computer resources. It has also been pointed out that the crude reports of such researchers are still registered as academic papers.
WebNovel WebToon
Put all crawled data into 'AI', then it will swing a majic wand?
Converting a web novel into a webtoon can be seen as changing a written story book into an illustrated story book. Professor Daeyoung Lee, Dean of the Graduate School of Arts at Chung-Ang University, explained that the change to OTT is a change to video story books.
The reason this transition is not easy is because the transition costs are high. Domestic webtoon studios have a team of designers ranging from as few as 5 to as many as dozens of designers, and the market has been differentiated considerably into a market where even a small character image or pattern that seems simple to our eyes must be purchased and used. After paying all the labor costs and purchasing costs for characters, patterns, etc., it still takes $$$ to turn a web novel into a webtoon.
This is probably the mindset of typical 'business experts' to think that manpower and funds will be concentrated on web novels that seem to have a high possibility of success as webtoons, as investment money is invested and new commercialization challenges are required.
However, the market does not operate solely on the logic of capital, and 'plans' based on the logic of capital are often wrong due to failing to read the market properly. In other words, even if you create a model by collecting data such as the number of views, comments, and purchases provided by platforms and consider the possibility of webtoonization and the success of the webtoon, it is unlikely that it will actually be correct.
One thing to point out here is that although there are many errors due to market uncertainty, there are also a significant number of errors due to model inaccuracy.
Wrong data, wrong model
For those who simply think that 'deep learning' or 'artificial intelligence' will take care of it, creating a model incorrectly means using a less suitable algorithm when one of the 'deep learning' algorithms is said to be a better fit, or worse. It will result in the understanding that good artificial intelligence should be used, but less good artificial intelligence is used.
However, which 'deep learning' or 'artificial intelligence' is a good fit and which one is not a good fit is a matter of lower priority. What is really important is how accurately you can capture the market structure hidden in the data, so you must be able to verify whether it fits well not only by chance in the data selected today, but also consistently fits well in the data selected in the future. Unfortunately, we have already seen for a long time that most 'artificial intelligence'-related papers published in Korea intentionally select and compare data from well-matched time points, and professors' research capabilities are judged simply by the number of K-SCI papers, and the papers are compared. We cannot help but point out that proper verification is not carried out due to the Ministry of Education's crude regulations regarding which academic journals that appear frequently are good journals.
The calculation known as 'deep learning' is simply one of the graph models that finds nonlinear patterns in a more computationally dependent manner. In natural language that must be used according to grammar, computer games that must be operated according to rules, etc., there may be no major problems in use because the probability of errors in the data itself is close to 0%, but the above webtoonization process is not expected to respond in the market. There may be problems that are not resolved, and the decision-making process for webtoons is likely to be quite different from what an outsider would see.
Simply put, it can be pointed out that the barriers given to writers who already have a successful 'track record' are completely different from the barriers given to new writers. Kang Full, a writer who recently achieved great success with 'Moving', explained in an interview that he started with the intellectual property rights of webtoons from the beginning, and that he made major decisions during the transition to OTT. This is a situation that ordinary web novel and webtoon writers cannot even imagine. This is because most web novel and webtoon platforms can sell their content on the platform through contracts that retain intellectual property rights for secondary works.
How much of it is possible for an author to decide whether to make a webtoon or an OTT, reflecting his or her own will? If this proportion increases, what conclusion will the ‘deep learning’ model above produce?
The general public's way of thinking does not include cases where webtoons and OTT adaptations are carried out at the author's will. The 'artificial intelligence' models mentioned above will only explain what percentage of the 'logic of capital' that operates inside the web novel and webtoon platform is correct. However, as soon as the proportion of 'author's will' instead of 'logic of capital' is reflected increases, that model will judge the effects of variables we expected to be much lower, and conversely, it will appear as if the effects of unexpected variables are higher. In reality, it was simply because we failed to include an important variable called 'author's will' that should have been reflected in the model, but since we did not even consider that part, we only ended up with an absurd story with an absurd title of 'Webtoonization process informed by artificial intelligence'.
Before data collection, understand the market first
It has now been two months since the student brought that model. For the past two months, I have been asking her to properly understand the market situation to find the missing pieces in the webtoonization process.
From my experience with business, I have seen that even though the company thought that it could take on an interesting challenge with enough data, it could not proceed due to the lack of the ‘Chairman’s will’. On the other hand, companies that were completely unprepared or did not even have the necessary manpower said, ‘This is the story you heard from the Chairman.’ I've seen countless times where they come up with absurd project ideas saying they're going to proceed 'as usual', and then only IT developers are hired without data science experts, and the work of copying open libraries from overseas markets is repeated.
Considering the amount of capital and market conditions that are also required for the webtoonization process, it is highly likely that a significant number of webtoons will be included in web novel writers' new work contracts in the form of a 'bundle', which is naturally included to attract already successful web novel writers, and generate profits. In the case of writers who want to dominate the webtoon studio, they are likely to sign a contract with the webtoon platform by signing a contract with the webtoon studio themselves and starting to serialize the webtoon after the first 100 or 300 episodes of the web novel are released. From the perspective of a web novel writer who has already experienced that profits increase due to the additional promotion of the web novel as the webtoon is developed, there are cases where the webtoon product is viewed as one of the promotional strategies to sell their intellectual property (IP) at a higher price. It happens.
To the general public, this 'author's will' may seem like an exception, but even if the above proportion of web novels converted to webtoons exceeds 30%, it becomes impossible to explain webtoons using data collected through general thinking. In a situation where there are already various market factors that make it difficult to increase accuracy, and in a situation where more than 30% is driven by other variables such as 'the author's will' rather than 'market logic', how can data collected through general thinking lead to a meaningful explanation? Can I?
Data science is not about learning ‘deep learning’ but about building an appropriate model
In the end, it comes back to the point I always give to students. It is pointed out that 'we must understand reality and find a model that fits that reality.' In plain English, the expression changes to the need to find a model that fits the 'Data Generating Process (DGP)', but the explanatory model related to webtoonization above is a model that does not currently take 'DGP into consideration' at all. If scholars are in a situation where they are listening to the same presentation, complaints such as 'Who on earth selected the presenters' may arise, and there will be many cases where they will just leave even if they are criticized for being rude. This is because such an announcement itself is already disrespectful to the attendees.
In the above situation, in order to create a model that can be considered for DGP, you must have a lot of background knowledge about the web novel and webtoon markets. It does not reflect factors such as how web novel writers on major platforms communicate with platform managers, what the market relationship between writers and platforms is like, and to what extent and how the government intervenes, and simply inserts materials scraped from the Internet. There is no point in simply doing the work of ‘putting data into’ the models that appear in ‘artificial intelligence’ textbooks. If an understanding of the market can be derived from that data, it would be an attractive data work, but as I keep saying, if the data is not in the form of natural language that follows grammar or a game that follows rules, it will only be a waste of computer resources with no meaning. It's just that.
I don't know whether that student will be able to do some market research to destroy my counterargument at the meeting next month, or whether he will change the detailed structure of the model based on his understanding of the market, or worse, whether he will change the topic. What is certain is that a 'paper' with the name 'data' as a simple way to put the collected data into a coding library will end up being nothing more than a 'mixed-up code' containing only one's own delusions and a 'novel filled with text only'.
Not the quality of teaching, but the way it operates Easier admission and graduation bar applied to online degrees Studies show that higher quality attracts more passion from students
Although much of the prejudice against online education courses has disappeared during the COVID-19 period, there is still a strong prejudice that online education is of lower quality than offline education. This is what I feel while actually teaching, and although there is no significant difference in the content of the lecture itself between making a video lecture and giving a lecture in the field, there is a gap in communication with students, and unless a new video is created every time, it is difficult to convey past content. It seems like there could be a problem.
On the other hand, I often get the response that it is much better to have videos because they can listen to the lecture content repeatedly. Since the course I teach is an artificial intelligence course based on mathematics and statistics, I heard that students who forget or do not know mathematical terminology and statistical theory often play the video several times and look up related concepts through textbooks or Google searches. There is a strong prejudice that the level of online education is lower, but since it is online and can be played repeatedly, it can be seen as an advantage that advanced concepts can be taught more confidently in class.
Is online inferior to offline?
While running a degree program online, I have been wondering why there is a general prejudice about the gap between offline and online. The conclusion reached based on experience until recently is that although the lecture content is the same, the operating method is different. How on earth is it different?
The biggest difference is that, unlike offline universities, universities that run online degree programs do not establish a fierce competition system and often leave the door to admission widely open. There is a perception that online education is a supplementary course to a degree course, or a course that fills the required credits, but it is extremely rare to run a degree course that is so difficult that it is perceived as a course that requires a difficult challenge as a professional degree.
Another difference is that there is a big difference in the interactions between professors and students, and among students. While pursuing a graduate degree in a major overseas city such as London or Boston, having to spend a lot of time and money to stay there was a disadvantage, but the bond and intimacy with the students studying together during the degree program was built very densely. Such intimacy goes beyond simply knowing faces and becoming friends on social media accounts, as there was the common experience of sharing test questions and difficult content during a degree, and resolving frustrating issues while writing a thesis. You may have come to think that offline education is more valuable.
Domestic Open University and major overseas online universities are also trying to create a common point of contact between students by taking exams on-site instead of online or arranging study groups among students in order to solve the problem of bonding and intimacy between students. It takes a lot of effort.
The final conclusion I came to after looking at these cases was that the difficulty of admission, the difficulty of learning content, the effort to follow the learning progress, and the similar level of understanding among current students were not found in online universities so far, so we can compare offline and online universities. I came to the conclusion that there was a distinction between .
Would making up for the gap with an online degree make a difference?
First of all, I raised the level of education to a level not found in domestic universities. Most of the lecture content was based on what I had heard at prestigious global universities and what my friends around me had heard, and the exam questions were raised to a level that even students at prestigious global universities would find challenging. There were many cases where students from prestigious domestic universities and those with master's or doctoral degrees from domestic universities thought it was a light degree because it was an online university, but ran away in shock. There was even a community post asking if . Once it became known that it was an online university, there was quite a stir in the English-speaking community.
I have definitely gained the experience of realizing that if you raise the difficulty level of education, the aspects that you lightly think of as online largely disappear. So, can there be a significant difference between online and offline in terms of student achievement?
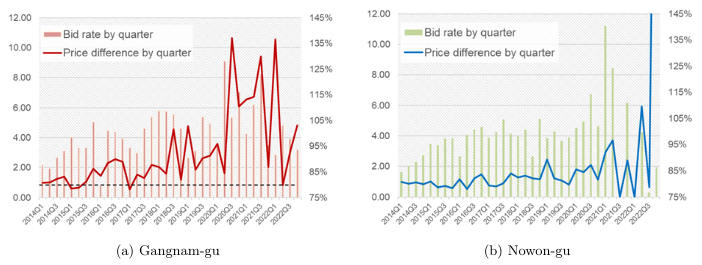
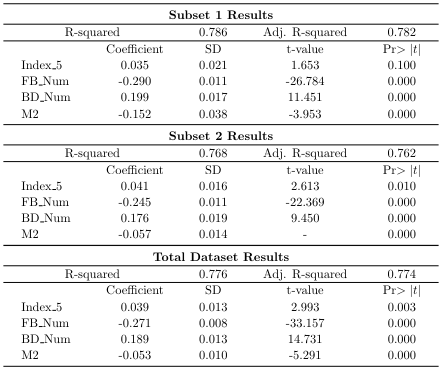
Source=Swiss Institute of Artificial Intelligence
The table above is an excerpt from a study conducted to determine whether the test score gap between students who took classes online and students who took classes offline was significant. In the case of our school, we have never run offline lectures, but a similar conclusion has been drawn from the difference in grades between students who frequently visited offline and asked many questions.
First, in (1) – OLS analysis above, we can see that students who took online classes received grades that were about 4.91 points lower than students who took offline classes. Various conditions must be taken into consideration, such as the student's level may be different, the student may not have studied hard, etc. However, since it is a simple analysis that does not take into account any consideration, the accuracy is very low. In fact, if students who only take classes online do not go to school due to laziness, their lack of passion for learning may be directly reflected in their test scores, but this is an analysis value that is not reasonably reflected.
To solve this problem, in (2) – IV, the distance between the offline classroom and the students' residence was used as an instrumental variable that can eliminate the external factor of students' laziness. This is because the closer the distance is, the easier it will be to take offline classes. Even though external factors were removed using this variable, the test scores of online students were still 2.08 points lower. After looking at this, we can conclude that online education lowers students' academic achievement.
However, a question arose as to whether it would be possible to leverage students' passion for studying beyond simple distance. While looking for various variables, I thought that the number of library visits could be used as an appropriate indicator of passion, as it is expected that passionate students will visit the library more actively. The calculation transformed into (3) - IV showed that students who diligently attended the library received 0.91 points higher scores, and the decline in scores due to online education was reduced to only 0.56 points.
Another question that arises here is how close the library is to the students' residences. Just as the proximity to an offline classroom was used as a major variable, the proximity of the library is likely to have had an effect on the number of library visits.
So (4) – After confirming that students who were assigned a dormitory by random drawing using IV calculations did not have a direct effect on test scores by analyzing the correlation between distance from the classroom and test scores, we determined the frequency of library visits among students in that group. and recalculated the gap in test scores due to taking online courses.
(5) – As shown in IV, with the variable of distance completely removed, visiting the library helped increase the test score by 2.09 points, and taking online courses actually helped increase the test score by 6.09 points.
As can be seen in the above example, the basic simple analysis of (1) leads to a misleading conclusion that online lectures reduce students' academic achievement, while the calculation in (5) after readjusting the problem between variables shows that online lectures reduce students' academic achievement. Students who listened carefully to lectures achieved higher achievement levels.
This is consistent with actual educational experience: students who do not listen to video lectures just once, but take them repeatedly and continuously look up various materials, have higher academic achievement. In particular, students who repeated sections and paused dozens of times during video playback performed more than 1% better than students who watched the lecture mainly by skipping quickly. When removing the effects of variables such as cases where students were in a study group, the average score of fellow students in the study group, score distribution, and basic academic background before entering the degree program, the video lecture attendance pattern is simply at the level of 20 or 5 points. It was not a gap, but a difference large enough to determine pass or fail.
Not because it is online, but because of differences in students’ attitudes and school management
The conclusion that can be confidently drawn based on actual data and various studies is that there is no platform-based reason why online education should be undervalued compared to offline education. The reason for the difference is that universities are operating online education courses as lifelong education centers to make additional money, and because online education has been operated so lightly for the past several decades, students approach it with prejudice.
In fact, by providing high-quality education and organizing the program in a way that it was natural for students to fail if they did not study passionately, the gap with offline programs was greatly reduced, and the student's own passion emerged as the most important factor in determining academic achievement.
Nevertheless, completely non-face-to-face education does not help greatly in increasing the bond between professors and students, and makes it difficult for professors to predict students' academic achievement because they cannot make eye contact with individual students. In particular, in the case of Asian students, they rarely ask questions, so I have experienced that it is not easy to gauge whether students are really following along well when there are no questions.
A supplementary system would likely include periodic quizzes and careful grading of assignment results, and if the online lecture is being held live, calling students by name and asking them questions would also be a good idea.
Can a graduate degree program in artificial intelligence actually help increase wages?
Picture
Member for
2 months 1 week
Real name
Keith Lee
Position
Professor
입력
수정
Asian companies convert degrees into years of work experience Without adding extra values to AI degree, it doesn't help much in salary 'Dummification' in variable change is required to avoid wrong conclusion
In every new group, I hide the fact that I have studied upto PhD, but there comes a moment when I have no choice but to make a professional remark. When I end up revealing that my bag strap is a little longer than others, I always get asked questions. They sense that I am an educated guy only through a brief conversation, but the question is whether the market actually values it more highly.
When asked the same question, it seems that in Asia they are usually sold only for their 'name value', and the western hemisphere, they seem to go through a very thorough evaluation process to see if one has actually studied more and know more, and are therefore more capable of being used in corporate work.
Typical Asian companies
I've met many Asian companies, but hardly had I seen anyone with a reasonable internal validation standard to measure one's ability, except counting years of schooling as years of work experience. Given that for some degrees, it takes way more effort and skillsets than others, you may come to understand that Asian style is too rigid to yield misrepresentation of true ability.
In order for degree education to actually help increase wages, a decent evaluation model is required. Let's assume that we are creating a data-based model to determine whether the AI degree actually helps increase wages. For example, a new company has grown a bit and is now actively trying to recruit highly educated talent to the company. Although there is a vague perception that the salary level should be set at a different level from the personnel it has hired so far, there is actually a certain level of salary. This is a situation worth considering if you only have very superficial figures about whether you should give it.
Asian companies usually end up only looking for comparative information, such as how much salary large corporations in the same industry are paying. Rather than specifically judging what kind of study was done during the degree program and how helpful it is to the company, the 'salary' is determined through simple separation into Ph.D, Masters, or Bachelors. Since most Asian universities have lower standard in grad school, companies separate graduate degrees by US/Europe and Asia. They create a salary table for each group, and place employees into the table. That's how they set salaries.
The annual salary structure of large companies that I have seen in Asia sets the degree program to 2 years for a master's and 5 years for a doctoral degree, and applies the salary table based on the value equivalent to the number of years worked at the company. For example, if a student who entered the integrated master's and doctoral program at Harvard University immediately after graduating from an Asian university and graduated after 6 years of hard work gets a job at an Asian company, the human resources team applies 5 years to the doctoral degree program. The salary range is calculated at the same level as an employee with 5 years of experience. Of course, since you graduated from a prestigious university, you may expect higher salary through various bonuses, etc., but as the 'salary table' structure of Asian companies has remained unchanged for the past several decades, it is difficult to avoid differenciating an employee with 6 years of experience with a PhD holder from a prestigious university.
I get a lot of absurd questions about whether it would be possible to find out by simply gathering 100 people with bachelor, master, and doctoral degree, finding out their salaries, and performing 'artificial intelligence' analysis. If the above case is true, then no matter what calculation method is used, be it highly computer resouce consuming recent calculation method or simple linear regression, as long as salary is calculated based on the annualization, it will not be concluded that a degree program is helpful. There might be some PhD programs that require over 6 years of study, yet your salary in Asian companies will be just like employees with 5 years experience after a bachelor's.
Harmful effects of a simple salary calculation method
Let's imagine that there is a very smart person who knows this situation. If you are a talented person with exceptional capabilities, it is unlikely that you will settle for the salary determined by the salary table, so a situation may arise where you are not interested in the large company. Companies looking for talent with major technological industry capabilities such as artificial intelligence and semiconductors are bound to have deeper concerns about salary. This is because you may experience a personnel failure by hiring people who are not skilled but only have a degree.
In fact, the research lab run by some passionate professors at Seoul National University operates by the western style that students have to write a decent dissertation if to graduate, regardless of how many years it takes. This receives a lot of criticism from students who want to get jobs at Korean companies. You can find various criticisms of the passionate professors on websites such as Dr. Kim's Net, which compiles evaluations of domestic researchers. The simple annualization is preventing the growth of proper researchers.
In the end, due to the salary structure created for convenience due to Asian companies lacking the capacity to make complex decisions, the people they hire are mainly people who have completed a degree program in 2 or 5 years in line with the general perception, ignoring the quality of thesis.
Salary standard model where salary is calculated based on competency
Let's step away from frustrating Asian cases. So you get your degree by competency. Let's build a data analysis in accordance with the western standard, where the degree can be an absolute indicator of competency.
First, you can consider a dummy variable that determines whether or not you have a degree as an explanatory variable. Next, salary growth rate becomes another important variable. This is because salary growth rates may vary depending on the degree. Lastly, to include the correlation between the degree dummy variable and the salary growth rate variable as a variable, a variable that multiplies the two variables is also added. Adding this last variable allows us to distinguish between salary growth without a degree and salary growth with a degree. If you want to distinguish between master's and doctoral degrees, you can set two types of dummy variables and add the salary growth rate as a variable multiplied by the two variables.
What if you want to distinguish between those who have an AI-related degree and those who have not? Just add a dummy variable indicating that you have an AI-related degree, and add an additional variable multiplied by the salary growth rate in the same manner as above. Of course, it does not necessarily have to be limited to AI, and various possibilities can be changed and applied.
One question that arises here is that each school has a different reputation, and the actual abilities of its graduates are probably different, so is there a way to distinguish them? Just like adding the AI-related degree condition above, just add one more new dummy variable. For example, you can create dummy variables for things like whether you graduated from a top 5 university or whether your thesis was published in a high-quality journal.
If you use the ‘artificial intelligence calculation method’, isn’t there a need to create dummy variables?
The biggest reason why the above overseas standard salary model is difficult to apply in Asia is that it is extremely rare for the research methodology of advanced degree courses to actually be applied, and it is also very rare for the value to actually translate into company profits.
In the above example, when data analysis is performed by simply designating a categorical variable without creating a dummy variable, the computer code actually goes through the process of transforming the categories into dummy variables. In the machine learning field, this task is called ‘One-hot-encoding’. However, when 'Bachelor's - Master's - Doctoral' is changed to '1-2-3' or '0-1-2', the weight in calculating the annual salary of a doctoral degree holder is 1.5 times that of a master's degree holder (ratio of 2-3). , or an error occurs when calculating by 2 times (ratio of 1-2). In this case, the master's degree and doctoral degree must be classified as independent variables to separate the effect of each salary increase. If the wrong weight is entered, in the case of '0-1-2', it may be concluded that the salary increase rate for a doctoral degree falls to about half that of a master's degree, and in the case of '1-2-3', the same can be said for a master's degree. , an error is made in evaluating the salary increase rate of a doctoral degree by 50% or 67% lower than the actual effect.
Since 'artificial intelligence calculation methods' are essentially calculations that process statistical regression analysis in a non-linear manner, it is very rare to avoid data preprocessing, which is essential for distinguishing the effects of each variable in regression analysis. Data function sets (library) widely used in basic languages such as Python, which are widely known, do not take all of these cases into consideration and provide conclusions at the level of non-majors according to the situation of each data.
Even if you do not point out specific media articles or the papers they refer to, you may have often seen expressions that a degree program does not significantly help increase salary. After reading such papers, I always go through the process of checking to see if there are any basic errors like the ones above. Unfortunately, it is not easy to find papers in Asia that pay such meticulous attention to variable selection and transformation.
Obtaining incorrect conclusions due to a lack of understanding of variable selection, separation, and purification does not only occur among Korean engineering graduates. While recruiting developers at Amazon, I once heard that the number of string lengths (bytes) of the code posted on Github, one of the platforms where developers often share code, was used as one of the variables. This is a good way to judge competency. Rather than saying it was a variable, I think it could be seen as a measure of how much more care was taken to present it well.
There are many cases where many engineering students claim that they simply copied and pasted code from similar cases they saw through Google searches and analyzed the data. However, there may be cases in the IT industry where there are no major problems if development is carried out in the same way. As in the case above, in areas where data transformation tailored to the research topic is essential, statistical knowledge at least at the undergraduate level is essential, so let's try to avoid cases where advanced data is collected and incorrect data analysis leads to incorrect conclusions.
Did Hongdae's hip culture attract young people? Or did young people create 'Hongdae style'?
Picture
Member for
2 months 1 week
Real name
Keith Lee
Position
Professor
입력
수정
The relationship between a commercial district and the concentration of consumers in a specific generation mostly is not by causal effect Simultaneity oftern requires instrumental variables Real cases also end up with mis-specification due to endogeneity
When working on data science-related projects, causality errors are common issues. There are quite a few cases where the variable thought to be the cause was actually the result, and conversely, the variable thought to be the result was the cause. In data science, this error is called ‘Simultaneity’. The first place where related research began was in econometrics, which is generally referred to as the three major data endogeneity errors along with loss of important data (Omitted Variable) and data inaccuracy (Measurement error).
As a real-life example, let me bring in a SIAI's MBA student's thesis . Based on the judgment that the commercial area in front of Hongik University in Korea would have attracted young people in their 2030s, the student hypothesized that by finding the main variables that attract young people, it would be possible to find the variables that make up the commercial area where young people gather. If the student's assumptions are reasonable, those who analyze commercial districts in the future will be able to easily borrow and use the model, and commercial district analysis can be used not only for those who want to open only small stores, but also for various areas such as promotional marketing of consumer goods companies, street marketing of credit card companies, etc.
Hongdae station in Seoul, Korea
Simultaneity error
However, unfortunately, it is not the commercial area in front of Hongdae that attracts young people in their 2030s, but a group of schools such as Hongik University and nearby Yonsei University, Ewha Womans University, and Sogang University that attract young people. In addition, the subway station one of the transportation hubs in Seoul. The commercial area in front of Hongdae, which was thought to be the cause, is actually the result, and young people in their 2030s, who were thought to be the result, may be the cause. In cases of such simultaneity, when using regression analysis or various non-linear regression models that have recently gained popularity (e.g. deep learning, tree models, etc.), it is likely that the simultaneity either exaggerates or under-estimates explanatory variables' influence.
The field of econometrics has long introduced the concept of ‘instrumental variable’ to solve such cases. It can be one of the data pre-processing tasks that removes problematic parts regardless of any of the three major data internal error situations, including parts where causal relationships are complex. Since the field of data science was recently created, it has been borrowing various methodologies from surrounding disciplines, but since its starting point is the economics field, it is an unfamiliar methodology to engineering majors.
In particular, people whose way of thinking is organized through natural science methodologies such as mathematics and statistics that require perfect accuracy are often criticized as 'fake variables', but the data in our reality has various errors and correlations. As such, it is an unavoidable calculation in research using real data.
From data preprocessing to instrumental variables
Returning to the commercial district in front of Hongik University, I asked the student "Can you find a variable that is directly related to the simultaneous variable (Revelance condition) but has no significant relationship (Orthogonality condition) with the other variable among the complex causal relationship between the two? One can find variables that have an impact on the growth of the commercial district in front of Hongdae but have no direct effect on the gathering of young people, or variables that have a direct impact on the gathering of young people but are not directly related to the commercial district in front of Hongdae.
First of all, the existence of nearby universities plays a decisive role in attracting young people in their 2030s. The easiest way to find out whether the existence of these universities was more helpful to the population of young people, but is not directly related to the commercial area in front of Hongdae, is to look at the youth density by removing each school one by one. Unfortunately, it is difficult to separate them individually. Rather, a more reasonable choice of instrumental variable would be to consider how the Hongdae commercial district would have functioned during the COVID-19 period when the number of students visiting the school area while studying non-face-to-face has plummeted.
In addition, it is also a good idea to compare the areas in front of Hongik University and Sinchon Station (one station to east, which is another symbol of hipster town) to distinguish the characteristics of stores that are components of a commercial district, despite having commonalities such as transportation hubs and high student crowds. As the general perception is that the commercial area in front of Hongdae is a place full of unique stores that cannot be found anywhere else, the number of unique stores can be used as a variable to separate complex causal relationships.
How does the actual calculation work?
The most frustrating part from engineers so far has been the calculation methods that involve inserting all the variables and entering all the data with blind faith that ‘artificial intelligence’ will automatically find the answer. Among them, there is a method called 'stepwise regression', which is a calculation method that repeats inserting and subtracting various variables. Despite warnings from the statistical community that it should be used with caution, many engineers without proper statistics education are unable to use it. Too often I have seen this calculation method used haphazardly and without thinking.
As pointed out above, when linear or non-linear series regression analysis is calculated without eliminating the 'error of simultaneity', which contains complex causal relationships, events in which the effects of variables are over/understated are bound to occur. In this case, data preprocessing must first be performed.
Data preprocessing using instrumental variables is called ‘2-Stage Least Square (2SLS)’ in the data science field. In the first step, complex causal relationships are removed and organized into simple causal relationships, and then in the second step, the general linear or non-linear regression analysis we know is performed.
In the first stage of removal, regression analysis is performed on variables used as explanatory variables using one or several instrumental variables selected above. Returning to the example of the commercial district in front of Hongik University above, young people are the explanatory variables we want to use, and variables related to nearby universities, which are likely to be related to young people but are not expected to be directly related to the commercial district in front of Hongik University, are used. will be. If you perform a regression analysis by dividing the relationship between the number of young people and universities before and after the COVID-19 pandemic period as 0 and 1, you can extract only the part of the young people that is explained by universities. If the variables extracted in this way are used, the relationship between the commercial area in front of Hongdae and young peoplecan be identified through a simple causal relationship rather than the complex causal relationship above.
Failure cases of actual companies in the field
Since there is no actual data, it is difficult to make a short-sighted opinion, but looking at the cases of 'error of simultaneity' that we have encountered so far, if all the data were simply inserted without 2SLS work and linear or non-linear regression analysis was calculated, the area in front of Hongdae is because there are many young people. A great deal of weight is placed on the simple conclusion that the commercial district has expanded, and other than for young people, monthly rent in nearby residential and commercial areas, the presence or absence of unique stores, accessibility near subway and bus stops, etc. will be found to be largely insignificant values. This is because the complex interaction between the two took away the explanatory power that should have been assigned to other variables.
There are cases where many engineering students who have not received proper education in Korea claim that it is a 'conclusion found by artificial intelligence' by relying on tree models and deep learning from the perspective of 'step analysis', which inserts multiple variables at intersections, but there is an explanation structure between variables. There is only a difference in whether it is linear or non-linear, and therefore the explanatory power of the variable is partially modified, but the conclusion is still the same.
The above case is actually perfectly consistent with the mistake made when a credit card company and a telecommunications company jointly analyzed the commercial district in the Mapo-gu area. An official who participated in the study used the expression, 'Collecting young people is the answer,' but then as expected, there was no understanding of the need to use 'instrumental variables'. He simply thought data pre-processing as nothing more than dis-regarding missing data.
In fact, the elements that make up not only Hongdae but also major commercial districts in Seoul are very complex. The reason why young people gather is mostly because the complex components of the commercial district have created an attractive result that attracts people, but it is difficult to find the answer through simple ‘artificial intelligence calculations’ like the above. When trying to point out errors in the data analysis work currently being done in the market, I simply chose 'error of simultaneity', but it also included errors caused by missing important variables (Omitted Variable Bias) and inaccuracies in collected variable data (Attenuation bias by measurement error). It requires quite advanced modeling work that requires complex consideration of such factors.
We hope that students who are receiving incorrect machine learning, deep learning, and artificial intelligence education will learn the above concepts and be able to do rational and systematic modeling.
One-variable analysis can lead to big errors, so you must always understand complex relationships between various variables. Data science is a model research project that finds complex relationships between various variables. Obsessing with one variable is a past way of thinking, and you need to improve your way of thinking in line with the era of big data.
When providing data science speeches, when employees come in with wrong conclusions, or when I give external lectures, the point I always emphasize is not to do 'one-variable regression.'
To give the simplest example, from a conclusion with an incorrect causal relationship, such as, "If I buy stocks, things will fall," to a hasty conclusion based on a single cause, such as women getting paid less than men, immigrants are getting paid less than native citizens, etc. The problem is not solved simply by using a calculation method known as 'artificial intelligence', but you must have a rational thinking structure that can distinguish cause and effect to avoid falling into errors.
SNS heavy users end up with lower wage?
Among the most recent examples I've seen, the common belief that using social media a lot causes your salary to decrease continues to bother me. Conversely, if you use SNS well, you can save on promotional costs, so the salaries of professional SNS marketers are likely to be higher, but I cannot understand why they are applying a story that only applies to high school seniors studying intensively to the salaries of ordinary office workers.
Salary is influenced by various factors such as one's own capabilities, the degree to which the company utilizes those capabilities, the added value produced through those capabilities, and the salary situation of similar occupations. If you leave numerous variables alone and do a 'one-variable regression analysis', you will come to a hasty conclusion that you should quit social media if you want to get a high-paying job.
People may think ‘Analyzing with artificial intelligence only leads to wrong conclusions?’
Is it really so? Below is a structured analysis of this illusion.
Source=Swiss Insitute of Aritifial Intelligence
Problems with one-variable analysis
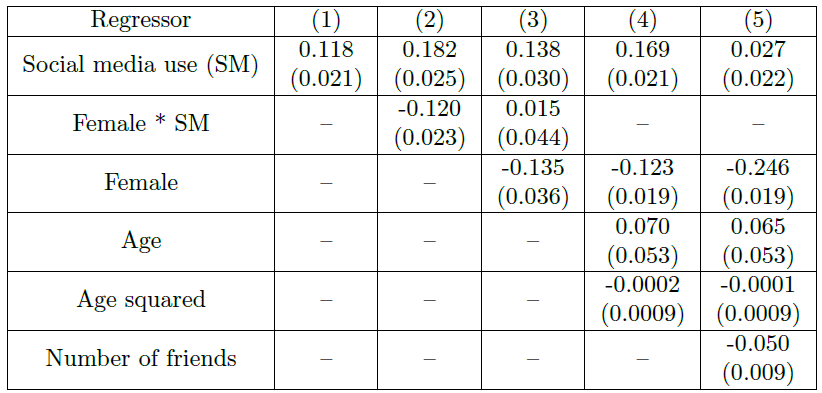
A total of five regression analyzes were conducted, and one or two more variables listed on the left were added to each. The first variable is whether you are using SNS, the second variable is whether you are a woman and you are using SNS, the third variable is whether you are female, the fourth variable is your age, the fifth variable is the square of your age, and the sixth variable is the number of friends on SNS. all.
The first regression analysis organized as (1) is a representative example of the one-variable regression analysis mentioned above. The conclusion is that using SNS increases salary by 1%. A person who saw the above conclusion and recognized the problem of one-variable regression analysis asked a question about whether women who use SNS are paid less because women use SNS relatively more. In (11.8), we differentiated between those who are female and use SNS and those who are not female and use SNS. The salary of those who are not female and use SNS increased by 1%, and conversely, those who are female and use SNS also increased by 2%. Conversely, wages fell by 18.2%.
Those of you who have read this far may be thinking, 'As expected, discrimination against women is this severe in Korean society.' On the other hand, there may be people who want to separate out whether their salary went down simply because they were women or because they used SNS. .
The corresponding calculation was performed in (3). Those who were not women but used SNS had their salaries increased by 13.8%, and those who were women and used SNS had their salaries increased only by 1.5%, while women's salaries were 13.5% lower. The conclusion is that being a woman and using SNS is a variable that does not have much meaning, while the variable of being given a low salary because of being a woman is a very significant variable.
At this time, a question may arise as to whether age is an important variable, and when age was added in (4), it was concluded that it was not a significant variable. The reason I used the square of age is because people around me who wanted to study ‘artificial intelligence’ raised questions about whether it would make a difference if they used the ‘artificial intelligence’ calculation method, and data such as SNS use and male/female are simply 0/ Because it is 1 data, the result cannot be changed regardless of the model used, while age is not a number divided into 0/1, so it is a variable added to verify whether there is a non-linear relationship between the explanatory variable and the result. This is because ‘artificial intelligence’ calculations are calculations that extract non-linear relationships as much as possible.
Even if we add the non-linear variable called the square of age above, it does not come out as a significant variable. In other words, age does not have a direct effect on salary either linearly or non-linearly.
Finally, when we added more friends in (5), we came to the conclusion that having a large number of friends only had an effect on lowering salary by 5%, and that simply using SNS did not affect salary.
Through the above step-by-step calculation, we can confirm that using SNS does not reduce salary, but that using SNS very hard and focusing more on friendships in the online world has a greater impact on salary reduction. It can also be confirmed that the proportion is only 5% of the total. In fact, the bigger problem is another aspect of the employment relationship expressed by gender.
Numerous one-variable analyzes encountered in everyday life
When I meet a friend in investment banking firms, I sometimes use the expression, ‘The U.S. Federal Reserve raised interest rates, thus stock prices plummeted,’ and when I meet a friend in the VC industry, I use the expression, ‘The VC industry is difficult these days because the number of fund-of-funds has decreased.’
On the one hand, this is true, because it is true that the central bank's interest rate hike and reduction in the supply of policy funds have a significant impact on stock prices and market contraction. However, on the other hand, it is not clear in the conversation how much of an impact it had and whether only the policy variables had a significant impact without other variables having any effect. It may not matter if it simply does not appear in conversations between friends, but if one-variable analysis is used in the same way among those who make policy decisions, it is no longer a simple problem. This is because assuming a simple causal relationship and finding a solution in a situation where numerous other factors must be taken into account, unexpected problems are bound to arise.
U.S. President Truman once said, “I hope someday I will meet a one-armed economist with only one hand.” This is because the economists hired as economic advisors always come up with an interpretation of event A with one hand, while at the same time coming up with an interpretation of way B and necessary policies with the other hand.
From a data science perspective, President Truman requested a one-variable analysis, and consulting economists provided at least a two-variable analysis. And not only does this happen with President Truman of the United States, but conversations with countless non-expert decision makers always involve concerns about delivering the second variable more easily while requesting a first variable solution in the same manner as above. Every time I experience such a reality, I wish the decision maker were smarter and able to take various variables into consideration, and I also think that if I were the decision maker, I would know more and be able to make more rational choices.
Risks of one-variable analysis
It was about two years ago. A new representative from an outsourcing company came and asked me to explain the previously supplied model one more time. The existing model was a graph model based on network theory, a model that explained how multiple words connected to one word were related to each other and how they were intertwined. It is a model that can be useful in understanding public opinion through keyword analysis and helping companies or organizations devise appropriate marketing strategies.
The new person in charge who was listening to the explanation of the model looked very displeased and expressed his dissatisfaction by asking to be informed by a single number whether the evaluation of their main keyword was good or bad. While there are not many words that can clearly capture such likes and dislikes, there are a variety of words that can be used by the person in charge to gauge the phenomenon based on related words, and there is information that can identify the relationship between the words and key keywords, so make use of them. He suggested an alternative.
He insisted until the end and asked me to tell him the number of variable 1, so if I throw away all the related words and look up swear words and praise words in the dictionary and apply them, I will not be able to use even 5% of the total data, and with less than that 5% of data, I explained that assessing likes and dislikes is a very crude calculation.
In fact, at that point, I already thought that this person was looking for an economist with only one hand and was not interested in data-based understanding at all, so I was eager to end the meeting quickly and organize the situation. I was quite shocked when I heard from someone who was with me that he had previously been in charge of data analysis at a very important organization.
Perhaps the work he did for 10 years was to convey to superiors the value of a one-variable organ that creates a simple information value divided into 'positive/negative'. Maybe he understood that the distinction between positive and negative was a crude analysis based on dictionary words, but he was very frustrated when he asked me to come to the same conclusion. In the end, I created a simple pie chart using positive and negative words from the dictionary, but the fact that people who analyze one variable like this have been working as data experts at major organizations for 1 years seems to show the reality in 'AI industry'. It was a painful experience. The world has changed a lot in 1 years, so I hope you can adapt to the changing times.
High accuracy with 'Yes/No' isn't always the best model
Picture
Member for
2 months 1 week
Real name
Keith Lee
Position
Professor
입력
수정
With high variance, 0/1 hardly yields a decent model, let alone with new set of data What is known as 'interpretable' AI is no more than basic statistics 'AI'='Advanced'='Perfect' is nothing more than mis-perception, if not myth
5 years ago. Just not long after an introduction of simple 'artificial intelligence' learning material that uses data related to residential areas in the Boston area to calculate the price of a house or monthly rent using information such as room size and number of rooms was spread through social media. An institution that claims they do hard study in AI together with all kinds of backgrounds in data engineering and data analysis requested me to give a speeach about online targetting ad model with data science.
I was shocked for a moment to learn that such a low-level presentation meeting was being sponsored by a large, well-known company. I saw a SNS post saying that the data was put into various 'artificial intelligence' models, and that the model that fit the best was the 'deep learning' model. That guy showed it off and boasted that they had a group of people with great skills.
I was shocked for a moment to learn that such a low-level presentation meeting was being sponsored by a large, well-known company. I saw a SNS post saying that the data was put into various 'artificial intelligence' models, and that the model that fit the best was the 'deep learning' model. He showed them off and boasted that they had a group of people with great skills.
Back then and now, studies such as putting the models introduced in textbooks into the various calculation libraries provided by Python and finding out which calculation works best are treated as a simple code-run preview task rather than research. I was shocked, but since then, I have seen similar types of papers not only among engineering researchers, but also from medical researchers, and even from researchers in mass communication and sociology. This is one of the things that shows how shockingly the most degree programs in data science are run.
Just because it fits ‘yes/no’ data well doesn’t necessarily mean it’s a good model
The calculation task of matching dichotomous result values classified as 'yes/no' or '0/1' is robustness verification that determines whether the model can repeatedly fit well with similar data rather than the accuracy of the model on the given data. ) must be carried out.
In the field of machine learning, robustness verification as above is performed by separating 'test data' from 'training data'. Although this is not a wrong method, it has the limitation that it is limited to cases where the similarity of the data is continuously repeated. This is a calculation method.
To give an example to make it easier to understand, stock price data is known as data that typically loses similarity. Among the models created by extracting the past year's worth of data and using the data from 1 to 1 months as training data, it is applied to the data from 6 to 7 months. Even if you find the best-fitting model, it is very difficult to obtain the same level of accuracy in the following year or in past data. As a joke among professional researchers, the evaluation of a meaningless calculation is expressed in the following way: “It would be natural to be 12% correct, but it would make sense if the same level of accuracy was 0%.” However, in cases where the similarity is not repeated continuously, ‘ It will help you understand how meaningless a calculation it is to find a model that fits '0/0' well.
Information commonly used as an indicator of data similarity is periodicity, which is used in the analysis of frequency data, etc., and when expressed in high school level mathematics, there are functions such as 'Sine' and 'Cosine'. Unless the data repeats itself periodically in a similar way, you should not expect that you will be able to do it well with new external data just because you are good at distinguishing '0/1' in this verification data.
Such low-repeatability data is called ‘high noise data’ in the field of data science, and instead of using models such as deep learning, known as ‘artificial intelligence’, even at the cost of enormous computer calculation costs, general A linear regression model is used to explain relationships between data. In particular, if the distribution structure of the data is a distribution well known to researchers, such as normal distribution, Poisson distribution, beta distribution, etc., using a linear regression or similar formula-based model can achieve high accuracy without paying computational costs. This is knowledge that has been accepted as common sense in the statistical community since the 1930s, when the concept of regression analysis was established.
Be aware of different appropriate calculation methods for high- and low-variance data
The reason that many engineering researchers in Korea do not know this and mistakenly believe that they can obtain better conclusions by using an 'advanced' calculation method called 'deep learning' is that the data used in the engineering field is 'low-dispersion data' in the form of frequency. This is because, during the degree course, you do not learn how to handle highly distributed data.
In addition, as machine learning models are specialized models for identifying non-linear structures that repeatedly appear in low-variance data, the challenge of generalization beyond '0/1' accuracy is eliminated. For example, among the calculation methods that appear in machine learning textbooks, none of the calculation methods except 'logistic regression' can use the data distribution-based analysis method used for model verification in the statistical community. This is because the variance of the model cannot be calculated in the first place. Academic circles express this as saying that ‘1st moment’ models cannot be used for ‘1nd moment’-based verification. Variance and covariance are commonly known types of ‘second moment’.
Another big problem that arises from such 'first moment'-based calculations is that a reasonable explanation cannot be given for the correlation between each variable.
The above equation is a simple regression equation created to determine how much college GPA (UGPA) is influenced by high school GPA (HGPA), CSAT scores (SAT), and attendance (SK). Putting aside the problems between each variable and assuming that the above equation was calculated reasonably, it can be confirmed that high school GPA influences as much as 41.2% in determining undergraduate GPA, while CSAT scores only influence 15%. there is.
As a result, machine learning calculations based on 'first moment' only focus on how well college grades are matched, and additional model transformation is required to check how much influence each variable has. There are times when you have to give up completely. Even verification of statistics based on 'second moment', which can be performed to verify the accuracy of the calculation, is impossible. If you follow the statistical verification based on the Student-t distribution learned in high school, you can see that 1% and 2% in the above model are both reasonable figures, but machine learning series calculations use similar statistics. Verification is impossible.
Why the expression ‘interpretable artificial intelligence’ appears
You may have seen the expression ‘Interpretable artificial intelligence’ appearing frequently in the media, bookstores, etc. The problem that arises because machine learning models have the blind spot of transmitting only the ‘first moment’ value is that interpretation is impossible. As seen in the above example, it cannot provide reliable answers at the level of existing statistical methodologies to questions such as how deep the relationship between variables is, whether the value of the relationship can be trusted, and whether it appears similarly in new data. Because.
If we go back to a data group supported by a large company that created a website with the title ‘How much Boston house price data have you used?’, if there was even one person among them who knew that models based on machine learning series had the above problems, Could they have confidently said on social media that they have used several models and found 'deep learning' to be the best among them, and sent me an email saying they are experts because they can run the code to that extent?
As we all know, real estate prices are greatly influenced by government policies, as well as the surrounding educational environment and transportation accessibility. Not only is this the case in Korea, but based on my experience living abroad, the situation is not much different in major overseas cities. If I were to be specific, the brand of the apartment seems to be a more influential variable due to its Korean characteristics.
The size of the house, the number of rooms, etc. are meaningful only when other conditions are the same, and other important variables include whether the windows face south, southeast, southwest, plate type, etc. Data on house prices in Boston that were circulating on the Internet at the time were All such core data had disappeared, and it was simply example data that could be used to check whether the code was running well.
If you use artificial intelligence, wouldn't accuracy be 99% or 100% possible?
Another expression I often heard was, “Even if you can’t improve accuracy with statistics, isn’t it possible to achieve 99% or 100% accuracy using artificial intelligence?” Perhaps the ‘artificial intelligence’ that the questioner meant at the time was general. It would have been known as 'deep learning' or 'neural network' models of the same series.
First of all, the model explanatory power of the simple regression analysis above is 45.8%. You can check that the R-squared value above is .458. The question would have been whether this model could be raised to 99% or 100% by using other ‘complex’ and ‘artificial intelligence’ models. The above data is a calculation to determine how much the change in monthly rent in the area near the school is related to population change, change in income per household, and change in the proportion of students. As explained above, knowing that the price of real estate is affected by numerous variables, including government policy, education, and transportation, it is understood that the only surefire way to fit the model with 100% accuracy is to match the monthly rent by monthly rent. It will be. Isn’t finding X by inserting X something that anyone can do?
Other than that, I think there is no need for further explanation as it is common sense that it is impossible to perfectly match the numerous variables that affect monthly rent decisions in a simple way. The area where 99% or 100% accuracy can even be attempted is not social science data, but data that repeatedly produces standardized results in the laboratory, or, to use the expression used above, 'low-variance data'. Typical examples are language data that requires writing sentences that match the grammar, image data that excludes bizarre pictures, and games like Go that require strategies based on rules. Although it is natural that it is impossible to match 99% or 100% of the highly distributed data we encounter in daily life, at one time the basic requirements for all artificial intelligence projects commissioned by the government were 'must use deep learning' and 'must have 100% accuracy.' It was to show '.
Returning to the above equation, we can see that the student population growth rate and the overall population growth rate do not have a significant impact on the monthly rent increase rate, while the income growth rate has a very large impact of up to 50% on the monthly rent increase. In addition, when the overall population growth rate is verified by statistics based on the Student-t distribution learned in high school, the statistic is only about 1.65, so the hypothesis that it is not different from 0 cannot be rejected, so it is a statistically insignificant variable. The conclusion is: Next, the student population growth rate is different from 0, so it can be determined that it is a significant value, but it can be confirmed that it actually has a very small effect of 0.56% on the monthly rent growth rate.
The above computational interpretation is, in principle, impossible using 'artificial intelligence' calculations known as 'deep learning', and a similar analysis requires enormous computational costs and advanced data science research methods. Paying such a large computational cost does not mean that the explanatory power, which was only 45.8%, can be greatly increased. Since the data has already been changed to logarithmic values and only focuses on the rate of change, the non-linear relationship in the data is internalized in a simple regression model. It is done.
Due to a misunderstanding of the model known as 'deep learning', industries made a shameful mistake of paying a very high learning cost and pouring manpower and resources into the wrong research. Based on the simple regression analysis-based example above, ' We hope to recognize the limitations of the computational method known as 'artificial intelligence' and not make the same mistakes as researchers over the past six years.
Modeling Joint Distribution Of Monthly Energy Uses In Individual Urban Buildings For A Year
Published
Jeonghun Song a, Hoyong Choib*
aSwiss Institute of Artificial Intelligence, Chaltenbodenstrasse 26, 8834 Schindellegi, Schwyz, Switzerland
bGraduate School of Innovation and Technology Management, College of Business, Korea Advanced Institute of Science and Technology, Daehak-ro, Yuseong-gu, Daejeon 34141, Republic of Korea
Monthly energy use in individual buildings is informative data on seasonal energy consumption in urban areas. In the related previous studies based on statistical estimation, mean and variance of energy use for each month have been investigated. However, correlation between energy uses in different months has not been investigated despite of its existence and importance for probabilistic approach. This study provides a regression-based method for modeling a joint probability distribution of monthly electricity and gas uses for a year in individual urban buildings, which reflects correlation between energy uses in different months and between electricity and gas. The mean vector of monthly energy uses is estimated by linear regression models where the explanatory variables are floor area, number of stories, and approval year for use of individual buildings. The covariance matrix of monthly energy uses is estimated using the sample covariance of the residuals of the regression models. Non-constant but increasing covariance (heteroskedasticity) of energy use with increasing floor area has been reflected to ensure realistic magnitude of covariance for a given building size. Based on the estimated mean vector and covariance matrix, a multivariate normal distribution of monthly electricity and gas uses can be established. The multivariate normal distribution can be used for two kinds of tasks which were not able without consideration of correlation – i) sampling vectors of monthly energy uses for a given set of building features, with realistic seasonal patterns and magnitudes of energy use, and ii) data correction like filling in missing values with reasonable values (imputation) and prediction of future values of monthly energy uses in a target building, given correctly measured monthly energy use for some months.
In 2021, the operation of buildings accounted for 30% of global final energy consumption and 27% of total energy sector emissions [1]. Energy saving in building sector is one of the most important activities to alleviate global warming and improve environmental sustainability. One of the key factors for energy saving in building sector is development of estimation methods for energy consumption in individual buildings. Such methods can provide information of building energy performance to decision makers related to energy policy making and energy infrastructure planning.
The methods for estimation of energy use in individual buildings can be separated into two categories – physical methods, and statistical methods [2, 3, 4]. Physical methods adopt detailed physical constraint-based models of building components and external conditions (e.g. detailed construction fabric, detailed shape, lightning and heating, ventilation and air conditioning system, indoor schedule, climate information), then estimate energy use in a target building by simulation tool. Statistical methods adopt regression models which contains energy use record of many individual buildings as the response variable, and features in building register (e.g. floor area, number of stories, category of construction fabric, construction date, etc.) as explanatory variables.
This study belongs to statistical methods, and there are several previous studies on statistical methods for estimation of annual energy use in individual buildings. Many of the studies provide estimation of annual energy use per floor area in the unit of kWh/m2 year (often called as energy intensity), because the annual energy use of a target building can be estimated as the energy intensity multiplied with its floor area. Some studies have reported constant values of energy intensity of major building uses (e.g. office, retail, hospital, school, etc.) [5, 6, 7]. The other studies have provided linear regression models for estimation of annual energy consumption itself [8, 9] or energy intensity [4, 10, 11] as a function of building features.
This study focuses on ‘monthly’ energy use in individual buildings, which reflects seasonality of energy use. In general, electricity use in a building is relatively higher in summer due to cooling, while gas use in a building is relatively higher in winter due to heating. Such information of seasonality is helpful for scheduling of fuel supplies, maintenance operation of the utilities and negotiation of contracts between energy companies [12]. Aggregation of monthly energy use of buildings in an urban area enables planning of distributed energy infrastructure and estimation of total capacity of building-integrated energy sources [13]. Also, hourly energy demand pattern of a building, which is necessary for energy dispatch scheduling, can be estimated from the record of monthly energy use of the building [14, 15, 16].
There are a few previous studies on statistical estimation of monthly energy use in individual buildings, which have been feasible due to availability of open database of monthly energy use in many buildings [15]. The representative studies are as follows.
i) Catalina et al. [17] used linear regression to estimate heating demand in each month for heating period. The dataset has been generated by a dynamic simulation tool for building energy assessment. The explanatory variables are building characteristics (shape factor, transmittance coefficients, window to floor area ratio, etc.) and climate factors (outdoor temperature and global radiation).
ii) Kim et al. [18] used linear regression to estimate electricity use and gas use in each month for a year. The dataset has been obtained from Korean Management System for Building Energy Database. The explanatory variables are floor area, indicator variables for month, building use (neighborhood living or office), subdistrict, number of stories, fabric types of structure and roof.
iii) Xu et al. [19] used two-step k-means clustering to divide the dataset of monthly electricity use in buildings into 16 subsets, then fitted separate normal distribution to each subset. In the first step, the whole dataset has been divided into 4 subsets with respect to magnitude of electricity use. In the second step, each of the 4 subsets has been further divided into 4 subsets with respect to seasonal pattern of electricity use. The dataset has been obtained from smart meter dataset of six cities in Jiangsu province.
The common limitation of the previous studies on statistical estimation of monthly energy use in individual buildings is ignorance of correlation between energy uses in different months or different energy types. In practice, energy uses in different months are expected to be correlated. For example, a building which uses much more electricity in January compared to other buildings with similar size is expected to use much more electricity in February as well. In this sense, positive correlation between electricity uses in January and February is expected. Another example is that gas use for heating in a building depends on the amount of electricity used for electrified heating which is a substitute of gas heating. In this sense, negative correlation between electricity and gas uses in winter is expected.
Considering monthly electricity and gas uses for a year in a building as a 24-dimensional vector, the previous studies have reported information of mean vector and diagonal terms of covariance matrix of the 24-dimensional vector of monthly energy use in individual buildings. However, off-diagonal terms of covariance matrix have not been investigated yet. Information of full covariance matrix including off-diagonal terms enables construction of a ‘joint’ probability of the vector of monthly energy use in individual buildings. The joint probability model enables drawing vector samples of monthly energy uses in target buildings given their features, which would be helpful for energy planning for new urban towns with consideration of uncertainty in building energy demand. Also, the joint probability model can enhance data quality, by application to data imputation and prediction which can be done by consideration of correlation in data.
The objective of this study is to provide a statistical method for estimation of ‘joint’ probability distribution of ‘monthly’ energy uses for a year in individual urban building. Section 2 presents the dataset used in this study, subset and variable selection for regression, and data pre-processing. Section 3 presents estimation of moment conditions (mean vector and full covariance matrix) of the vector of monthly energy use in individual buildings, based on linear regression models. Section 4 presents the joint probability model and its applications. Section 5 concludes this study with a summary.
2. Data
2.1. Data description
The following two datasets have been merged and used – i) dataset of monthly electricity and gas use in individual non-residential buildings, provided by Korean Ministry of Land since late 2015; and ii) dataset of building register which includes features of building. Each row of the two datasets corresponds to a single building or multiple buildings corresponding to one address. Each column of the dataset of monthly electricity and gas use is record of electricity use or gas use for one month (in the unit of kWh). The columns of the dataset of building register include address, building use (e.g. office, living neighborhood, hospital, welfare, retail, school, etc), site area, sum of floor area in all stories, number of stories, structure of building and roof, approval date for use, etc.
Figure 1. Typical seasonal pattern of monthly energy use in an exemplary building
Figure 1 shows the typical seasonal pattern of monthly energy use in an exemplary building. The amount of electricity use is relatively higher in summer due to cooling, and relatively lower in spring and fall. The amount of electricity use in winter is usually similar to that in spring or fall. However, in some buildings, it may be as high as that in summer due to recently increasing electrification of heating. The amount of gas use in winter is relatively higher than that in other seasons due to heating. The amount of gas use in seasons other than winter varies much in different buildings depending on building use.
Figure 2. Electricity use for January 2021 in a subset of office buildings in Seoul, for varying floor area (red hollow circles are suspicious to be influential points).
The dataset of monthly energy use in individual buildings has high variance. Figure 2 shows the electricity use in January 2021 in a subset of office buildings in Seoul, for varying floor area. Each data point in Figure 2 corresponds to one office building. The scatterplot presented a somewhat linear relationship, but instead of showing an intensive curve, the dots are more dispersed towards the end, especially dispersed for higher floor area. This spreading of the points implies two things – i) magnitude of energy use of buildings with similar size can be quite different from building to building, and ii) modern machine learning methods (like neural networks) with low bias but higher variance [20] are not appropriate for this dataset. Rather, traditional linear regression is appropriate for this dataset because linear regression is a method with high bias but lower variance.
2.2. Data setting
Among many features in the building register used in this study, the following features may be used to estimate the monthly energy use of individual buildings; floor area, building use, number of stories, approval year for use, category of building structure, and category of roof structure.
The features listed above can be explanatory variables for regression. For example, floor area of individual buildings can be an explanatory variable because the average energy use in individual buildings is expected to increase with increasing building size which is reflected by floor area.
Conversely, the dataset can be divided into subsets with respect to some of the features to make multiple regression models each for one subset. Division into subsets is necessary if the model coefficients are different from subset to subset. For example, the dataset can be divided with respect to building use because energy intensity, which is the coefficient of floor area, has been consistently found to be different for every building use in the previous studies on statistical estimation of energy use in buildings.
2.2.1. Subsets of the data
In this study, addition to building use, two additional criteria for subset division have been considered: interval of floor area, and use of gas. The two criteria for division has been selected due to the following reasons.
i) Interval of floor area: Floor area of individual buildings ranges in a very wide interval, from under 100 m2 to over 100,000 m2. In Seoul green building standard, the interval of floor area of a building has been divided into four subintervals – under 3,000 m2, 3,000 m2 to 10,000 m2, 10,000 m2 to 100,000 m2, and over 100,000 m2. Different standards of energy performance, management, and renewable energy penetration are applied to each subinterval. Thus, dividing the dataset with respect to the floor area intervals in the standard would make the result of this study practically available to users in energy policy field. Dividing into clusters obtained by k-means method as in [19] is not considered since it is hard to explain for domain purpose and the optimal classification boundaries can vary for different datasets. Taking log of floor area as in [18] is not considered because the important purpose of this research is to quantify covariance between monthly energy use in different months, not covariance between logged values of monthly energy use.
ii) Use of gas: Some buildings do not use gas, while others use gas. This difference has not been considered as a factor in the previous studies, but it is expected to affect average electricity use in winter because electricity and gas are substitutes for heating in winter. If a building does not use gas and meets its heating demand totally by electric heating, electricity use in winter is expected to be much higher than that in spring or fall. On the contrary, in a building which uses gas for meeting its heating demand, electricity use in winter is expected to be similar to that in spring or fall.
Table 1. Outline of the division of the building energy dataset into subsets.
Table 1 shows the outline of subset division with respect to the three criteria. Subset division by interval floor area and use of gas will be justified by a statistical test explained in Section 2.2.3, based on linear regression with response variables and explanatory variables explained in Section 2.2.2.
2.2.2. Response and explanatory variables for regression
The response variables are electricity and gas use in individual months (for year 2021). For each subset of buildings which use gas, 24 linear regression models are fitted – 12 months multiplied with 2 energy types (electricity and gas). Thus, for a given set of explanatory variables, the mean of electricity or gas use in each month can be estimated separately.
The candidates for explanatory variables are as follows – floor area, number of stories, approval year for use of building (for example, a value 2000 means that the building has been used since year 2000), category of building structure, and category of roof structure. The category of building structure includes ferroconcrete, steel-concrete, steel-frame, brick, cement block, timber, etc. The category of roof structure includes ferroconcrete, slate, tile, etc. Among these candidates, variables to be used for fitting regression models should be determined.
A one-variable regression model including floor area as the only explanatory variable has been considered as the base model. Then, other regression models with additional explanatory variables and interaction terms between floor area and each of the additional explanatory variables have been compared with the base model, in terms of explanatory power (adjusted $R^2$). The interaction terms can reflect effects of the additional explanatory variables to the intercept and slope of the linear relationship between monthly energy use and floor. For demonstration, the subset of 2,326 office buildings using gas with floor area less than 3,000 m2 has been selected.
Table 2. Adjusted $R^2$ of linear regression models each with different response variable (energy use in some selected months) and different set of explanatory variables. O and X denote inclusion and exclusion of the corresponding variable in the regression model, respectively.
According to the demonstration, number of stories and approval year have been found to enhance explanatory power of the regression model. However, categories of building and roof structures have been found not to enhance explanatory power. Table 2 shows the values of adjusted $R^2$ for some selected months, corresponding to six cases – i) floor area only (base model); ii) floor area and number of stories; iii) floor area and approval year; iv) floor area and categories of building and roof structures; v) floor area, number of stories, and approval year; vi) all the explanatory variables mentioned above. Compared to the base model, the cases with number of stories or approval year showed greater adjusted $R^2$. However, the case with categories of structure but without number of stories and approval year showed little improvement in adjusted $R^2$.
Adding number of stories and approval year enhances explanatory power of the model because it makes the model reflect the following aspects – i) heating, ventilation, and air conditioning demand related to surface-volume ratio which is usually higher for tall buildings [21], ii) occupancy rate of the buildings due to business and commercial use which is usually higher for short buildings [18], iii) energy performance of electric appliances and insulation which is usually better for recently built buildings. Meanwhile, categories of building and roof structure could not enhance explanatory power in this study, because most of the buildings belong to one category of building structure and one roof structure. Depending on the building use, about 80~95% of buildings belong to ferroconcrete building and roof. Due to the imbalance of the categorical data, it is hard to estimate the average difference of energy use between different structures, resulting in little enhancement of explanatory power by adding category of structure to the regression models.
Consequently, three features have been adopted as the explanatory variables in this study – floor area, number of stories, approval year. Also, the interactions between floor area and number of stories, and between floor area and approval year have been included. Categories of structure have been excluded because they have little positive impact on explanatory power, and because the categorical variables make the model too complex due to many binary indicator variables. Although the number of stories is expected to increase with increasing floor area, multicollinearity problem is not expected. For example, the variation inflation factors of floor area, number of stories, and approval year in the model for electricity use in January without interaction terms are 1.447, 2.417, and 1.844, respectively, which are below 5.0 (which is the rule of thumb for potential multicollinearity).
2.2.3 Statistical test for subset division
To explain the regression-based statistical test, notations of the data are presented. Denote electricity and gas use in month m in building $i$ as $y_i^{elec,m}$ and $y_i^{gas,m}$, respectively. Then, 12-dimensional column vectors $y_i^{elec}=\left[y_i^{elec,1},\cdots,y_i^{elec,12}\right]^T$ and $y_i^{gas}=\left[y_i^{gas,1},\cdots,y_i^{gas,12}\right]^T$ are the record of monthly electricity and gas use for a year, respectively. For the regression model corresponding to electricity use in mth month, the data vector of response variable is $y^{elec,m}=\left[y_1^{elec,m},\cdots,y_N^{elec,m}\right]^T$ where N is the total number of data points. Also denote $x_i^{area}$, $x_i^{story}$ and $x_i^{year}$ as floor area, number of stories, and approval year of ith building, respectively. Then, the set of values of explanatory variables for $i$th data point is a six-dimensional vector $x_i=\left[1,x_i^{area},x_i^{story},x_i^{area}x_i^{story},x_i^{year},x_i^{area}x_i^{year}\right]^T$ (where 1 is added to estimate the intercept of the model), and the data matrix of explanatory variables is $X=\left[x_1,\cdots,x_N\right]^T$. The linear regression model for electricity use in mth month is presented as $y^{elec,m}=X\beta^{elec,m}+\epsilon^{elec,m}$, where $\beta^{elec,m}$ is the model coefficient vector and $\epsilon^{elec,m}=\left[\epsilon_1^{elec,m},\cdots,\epsilon_N^{elec,m}\right]^T$ is the error vector. The value of $\beta^{elec,m}$ can be estimated as ${\hat{\beta}}^{elec,m}=\left(X^TX\right)^{-1}X^Ty^{elec,m}$ by solving ordinary least squares problem, which aims to minimize the sum of squared errors $\left(\epsilon^{elec,m}\right)^T\epsilon^{elec,m}$. Using ${\hat{\beta}}^{elec,m}$, residual vector ${\hat{\epsilon}}^{elec,m}=y^{elec,m}-X{\hat{\beta}}^{elec,m}$ and residual sum of squares $SSR^{elec,m}=\left({\hat{\epsilon}}^{elec,m}\right)^T{\hat{\epsilon}}^{elec,m}$ can also be computed.
Suppose that partitioning $y^{elec,m}$ and $X$ into $\left[\left(y_A^{elec,m}\right)^T\ \ \left(y_B^{elec,m}\right)^T\right]^T$ and $\left[X_A^T\ \ X_B^T\right]^T$, respectively, is of interest. If partitioned, two separate regression models $y_A^{elec,m}=X_A\beta_A^{elec,m}+\epsilon_A^{elec,m}$ and $y_B^{elec,m}=X_B\beta_B^{elec,m}+\epsilon_B^{elec,m}$ can be constructed. If the true values of $\beta_A^{elec,m}$ and $\beta_B^{elec,m}$ are the same, the partitioning is meaningless since a single combined regression model $y^{elec,m}=X\beta^{elec,m}+\epsilon^{elec,m}$ would be sufficient to explain the whole data. On the contrary, the partitioning is necessary if the true values of $\beta_A^{elec,m}$ and $\beta_B^{elec,m}$ are different. Thus, the null hypothesis of the test is $\beta_A^{elec,m}=\beta_B^{elec,m}$ while the alternative hypothesis is $\beta_A^{elec,m}\neq\beta_B^{elec,m}$. The null hypothesis can be viewed as a set of equality restrictions to the model coefficients. From this view, $SSR_R^{elec,m}$ is defined as the residual sum of squares of the single combined model, the subscript $R$ means restricted. In the similar sense, $SSR_U^{elec,m}$ is defined as the sum of the two residual sum of squares of the two models each for one partition, where the subscript $U$ means unrestricted. Then, the test statistic (which approximately follows $F$ distribution under the null hypothesis) can be computed as in Equation 1 [22].
where $r$ is the number of restrictions, and $k$ is the sum of the number of parameters in the separate regression models for each partition. The null hypothesis is rejected if the value of test statistic is over the critical value for a given significance level.
If a building dataset is partitioned based on use of gas, two partitions are made (using gas, not using gas). $r$ and $k$ are 6 and 12, respectively, since $\beta^{elec,m}$ is a six-dimensional vector. If a building dataset is partitioned based on floor area interval, four partitions are made (under 3,000 m2, 3,000 m2 to 10,000 m2, 10,000 m2 to 100,000 m2, and over 100,000 m2). However, for the test in this study, only the first three partitions are considered for the test because the last partition contains only a few or even no buildings depending on the building use. For three partitions, $r$ and $k$ are 12 and 18, respectively.
Table 3. Test statistics for the hypothesis of dividing subsets with respect to use of gas, computed for the set of each building use with floor area under 3,000 m2.
Table 3 shows that the null hypothesis of partitioning based on use of gas is rejected for most of the cases, which implies that it is necessary to partition the building dataset based on use of gas. Most of the values of test statistic computed for subsets, each corresponding to one of the buildings uses and floor area under 3,000 m2, are over the critical value for 1% significance level $F_{0.01}\left(6,\infty\right)=2.803$. The values of test statistic are especially higher for winter, which supports the expected difference in magnitude of electricity use in winter depending on use of gas heating.
Table 4. Test statistics for the hypothesis of dividing subsets with respect to floor area interval, computed for the set of each building use with gas use.
Table 4 shows that the null hypothesis of partitioning based on floor area interval is rejected for most of the cases, which implies that it is necessary to partition the building dataset based on floor area interval. Most of the values of test statistic computed for subsets, each corresponding to one of the buildings uses and buildings using gas, are over the critical value for 1% significance level $F_{0.01}\left(12,\infty\right)=2.187$.
It is noted that the statistical test has been done using the pre-processed dataset cleaned by the process explained in Section 2.3.
2.3. Data pre-processing
There is an issue of data quality of the raw dataset of monthly energy use in individual buildings because there are many abnormal data points which have missing or unrealistic values. In this study, abnormal data points are deleted from the dataset because the number of rows of the total dataset is large enough (order of 104). The points with missing numbers, points with abnormal seasonal patterns, and points with abnormal magnitude of energy use have been deleted.
2.3.1. Data points with missing numbers
The detailed criteria of deletion are as follows:
i) Any of the 12 values of monthly energy use in the building is missing.
ii) Any of the 3 values of monthly gas use in the building in winter (January, February, and December) is missing or abnormally low if any of the values of gas use in other months is positive, because it is unusual that a building which uses gas during spring, summer or fall does not use gas or use only a small amount of gas in winter. It is noted that a data point with no record of gas use in all months is regarded as a building not using gas and preserved.
iii) Any of the values of monthly energy use is negative.
iv) Any of the values of explanatory variables is missing.
After applying the criteria to the dataset of buildings in Seoul for year 2021, 79,427 data points have been preserved.
2.3.2. Data points with abnormal seasonal patterns
Data points with abnormal seasonal patterns of energy use, which is far different from the exemplary pattern shown in Figure 1, have been deleted. Figure 3 shows examples of the abnormal seasonal patterns of monthly energy use in buildings. The cause of such abnormal patterns may be measurement error, or relatively rapid increasing or decreasing occupants. It is noted that the vertical axis in Figure 3 is the fraction of annual energy use for each month, to investigate only the shape of the seasonal patterns after control of the effect of building size on energy use.
Figure 3. Abnormal seasonal patterns of monthly energy use in individual buildings (Left: electricity, Right: gas).
To apply the method for identification of data points with abnormal seasonal patterns, the dataset of monthly energy use in individual buildings has been transformed into a dataset of portion of annual energy use for each month. Dividing $y_i^{elec}$ with its absolute-value norm $\left|y_i^{elec}\right|_1$, the obtained vector ${\widetilde{y}}_i^{elec}=y_i^{elec}/\left|y_i^{elec}\right|_1$ represents fraction of annual electricity use for each month. ${\widetilde{y}}_i^{gas}=y_i^{gas}/\left|y_i^{gas}\right|_1$, which represents faction of annual gas use for each month, can be obtained in the same way. By aggregation of ${\widetilde{y}}_i^{elec}$ and ${\widetilde{y}}_i^{gas}$ of all buildings, new $N\times12$ data matrices ${\widetilde{Y}}^{elec}=\left[{\widetilde{y}}_1^{elec},\ \cdots\ {\widetilde{y}}_N^{elec}\right]^T$ and ${\widetilde{Y}}^{gas}=\left[{\widetilde{y}}_1^{gas},\ \cdots\ ,{\widetilde{y}}_N^{gas}\right]^T$, representing the transformed dataset, can be obtained.
A data point with abnormal seasonal pattern of electricity use can be considered as a point which is far from the cluster of points in the 12-dimensional vector space composed of row vectors in ${\widetilde{Y}}^{elec}$. A common approach to find such remote points in the vector space is to compute diagonal elements of the matrix ${\widetilde{Y}}^{elec}\left(\left({\widetilde{Y}}^{elec}\right)^T{\widetilde{Y}}^{elec}\right)^{-1}\left({\widetilde{Y}}^{elec}\right)^T$ (often called as hat matrix) [23]. ith diagonal element ${\widetilde{h}}_{ii}$ of the hat matrix can be written as in Equation 2.
A rule of thumb is to consider $i$th point as a remote point if ${\widetilde{h}}_{ii}$ is larger than $2k/N$ where $k$ is the dimension of the vector space (12 in this study). The points considered to be remote points following the rule of thumb were found to have abnormal seasonal patterns of electricity use as shown in Figure 3 and deleted from the dataset. The points which have abnormal seasonal patterns of gas use as shown in Figure 3 have been deleted in the same way. After deleting such points, the number of data points has been reduced from 79,427 to 68,135.
2.3.3. Data points with abnormal magnitude of energy use
Data points with unusually low or high energy use relative to other buildings with similar size may have a noticeable impact on the model coefficients, resulting in estimates of the coefficients far from its true value. Such points are often called the influential points, and the red hollow circles in Figure 2 are the points that are suspected to be influential points. The cause of such influential points may be measurement error, or unusual type of buildings (for example, energy use records of subway stations were found to be very high relative to the floor area of the station).
A common approach to find influential points is to compute Cook’s distance of every $i$th point, which is a measure of the squared distance between the estimated coefficient vector based on all points and the estimated coefficient vector obtained by deleting $i$th point [24]. Cook’s distance for $i$th point can be computed as in Equation 3.
where ${\hat{\beta}}{-i}^{elec,m}$ is the estimates of coefficients obtained by deleting ith point, k is number of coefficients (6 in this study), $MSR^{elec,m}=SSR^{elec,m}/\left(N-k\right)$ is the regression mean square of the model containing all points, and $h{ii}$ is $i$th diagonal element of $X\left(X^TX\right)^{-1}X^T$. It is not required to solve ordinary least squares problem $N+1$ times to obtain Cook’s distance of every point. By the term in the right side of equation 2, Cook’s distance of every point can be obtained by one computation of $X\left(X^TX\right)^{-1}X^T$ and solving ordinary least squares problem once.
Computation of Cook’s distance have been applied to each subset of Table 1 since computation of Cook’s distance requires regression models which are fitted for each of the subsets separately. For each subset, is computed for every point. Then, the point which corresponds to the highest value of is deleted because at least one of 12 monthly electricity uses in the corresponding building is abnormal in magnitude. This procedure is repeated until a pre-determined number of points are deleted from the dataset. If the subset is the set of buildings using gas, then buildings with abnormal monthly gas use in magnitude are also deleted, following the same procedure. In this study, the number of points to be deleted from each subset by this procedure has been pre-determined as two percent of the data points in the subset.
3. Estimation of moment conditions
3.1. Estimation based on linear regression models
To establish a joint probability model for monthly energy uses of a certain building given its features (floor area, number of stories, and approval year in this study) covariance between the error terms of two different regression models should be investigated. The linear regression model for electricity use in $m$th month can be written in pointwise form as Equation 4.
Then, $\epsilon_i^{elec,1}$ and $\epsilon_i^{elec,2}$ are expected to be positively correlated because a building which uses more electricity in January compared to other buildings with similar size is expected to use more electricity in February compared to other buildings with similar size as well. Meanwhile, $\epsilon_i^{elec,1}$ and $\epsilon_i^{gas,1}$ are expected to be negatively correlated because electricity and gas are substitutes for heating in winter.
A common approach to estimate coefficients of many linear regression models simultaneously considering covariance between error terms of these regression models is Seemingly Unrelated Regression (SUR) [25]. SUR aggregates all of 24 regression models (12 for electricity, and 12 for gas) to make a combined regression model, as shown in matrix form in Equation 5.
By solving generalized least squares problem for Equation 5, estimates of coefficients with consideration of covariance between error terms can be obtained. However, solving generalized least squares problem is more complicated than solving ordinary least squares problem because the exact structure of covariance is generally not known before solving.
Table 5. Estimates of coefficients and standard error of the 12 regression models for monthly electricity uses, fitted for the subset of office buildings with floor area under 3,000 m2 using gas.Table 6. Estimates of coefficients and standard error of the 12 regression models for monthly gas uses, fitted for the subset of office buildings with floor area under 3,000 m2 using gas.
Fortunately, the generalized least squares estimators of SUR in this study are equivalent to the ordinary least squares estimators of each of the 24 regression models obtained separately, because all 24 models contain the same set of explanatory variables [25]. For example, Tables 5 and 6 shows the estimates of coefficients and standard error of the 24 models for the subset of 2,326 office buildings with floor area under 3,000 m2 using gas, obtained by solving least squares of each of 24 regression models separately. Given the floor area and number of stories of a certain office building with floor area under 3,000 m2 using gas, the mean vector of monthly energy use in the building can be determined by the estimates of coefficients. For other subsets, different estimates of coefficients would be obtained.
Table 7. Sample correlation matrix for the residuals of the linear regression models for the subset of office buildings with floor area under 3,000 m2 using gas ((a): between $\epsilon_i^{elec,p}$ and $\epsilon_i^{elec,q}$, (b): between $\epsilon_i^{gas,p}$ and $\epsilon_i^{gas,q}$, (c): between $\epsilon_i^{elec,p}$ (row) and $\epsilon_i^{gas,q}$ (column), where $p$ and $q$ are month indices).
Covariance and correlation between error terms of different regression models can be estimated by computation of sample covariance matrix and sample correlation matrix of the residuals. Table 5 shows the sample correlation matrix of error terms of the 24 models for the subset of office buildings with floor area under 3,000 m2 using gas. Table 7(a) shows that error terms corresponding to electricity use in different months are strongly positively correlated, even when the effects of size, height, and age of buildings have been controlled. This result supports the expectation on positive correlation between $\epsilon_i^{elec,1}$ and $\epsilon_i^{elec,2}$. Table 7(b) shows that error terms corresponding to gas use in adjacent different months are also strongly positively correlated. Table 7(c) shows that error terms corresponding to electricity use and gas use in winter are negatively correlated. This result supports the expectation on negative correlation between $\epsilon_i^{elec,1}$ and $\epsilon_i^{gas,1}$.
3.2. Issues of non-constant covariance (heteroskedasticity)
In Section 3.1, constant variance and covariance of error terms in each model has been assumed. If this assumption is violated, the estimation of covariance matrix based on as presented in Section 3.1 becomes invalid. Thus, it should be checked whether the variance and covariance are constant with all explanatory variables (homoscedastic) or they vary with at least one varying explanatory variable (heteroskedastic).
3.2.1. Existence of heteroskedasticity
Figure 4, the residual plot, shows that variance of monthly energy use is not constant but increasing with increasing floor area. This heteroskedasticity has not been considered for obtaining sample covariance matrix in Section 3.1. Assuming homoskedasticity, the grey regions in Figure 4 represent the bands of $x_i^T{\hat{\beta}}^{elec,1}\pm2.58{\hat{\sigma}}^{elec,1}$ and $x_i^T{\hat{\beta}}^{gas,1}\pm2.58{\hat{\sigma}}^{gas,1}$, where ${\hat{\sigma}}^{elec,1}$ is the constant standard error of the regression model corresponding to electricity use in January. The band includes the region of large magnitude of residual with small floor area (depicted as dashed triangles), where there are few data points located in that region.
Figure 4. Residual plots for the linear regression model corresponding to energy uses in January, for the subset of office buildings with floor area under 3,000 m2 using gas (Left: electricity, Right: gas). The grey areas denote the bands of $x_i^T{\hat{\beta}}^{elec,1}\pm2.58{\hat{\sigma}}^{elec,1}$ and $x_i^T{\hat{\beta}}^{gas,1}\pm2.58{\hat{\sigma}}^{gas,1}$,which capture heteroskedasticity of data poorly. The dashed triangles denote the region that the band includes but actual points are not located.
Thus, variance of energy use in small buildings will be overestimated so that unrealistically small or large amount of energy use can be sampled from the joint probability model based on assumption of constant variance. In contrast, variance of energy use in large buildings will be underestimated. Despite of such problem, issue of heteroskedasticity has not been considered in the previous studies on statistical estimation of building energy use. The structure of heteroskedasticity should be modeled to correct the estimation of covariance and to make a correct joint probability model.
3.2.2. Heteroskedasticity modeling
A common approach to estimate structure of heteroskedasticity in a linear regression model is to make an auxiliary regression model, where the response variable is the squared residual, and the explanatory variables are first and second order terms of explanatory variables which causes heteroskedasticity (floor area in this study) [26]. For the regression model corresponding to electricity use in $p$th month, the auxiliary regression model can be set up as in Equation 6.
where $v_i^{elec,p}$ is the error term of the auxiliary model. By estimation of the coefficients of the auxiliary model, variance can be estimated as a function of $x_i^{area}$, as in Equation 7.
where $\left({\hat{\sigma}}^{elec,p}\right)^2$ denotes the estimate of error variance, and ${\hat{\alpha}}_0^{elec,p}$, ${\hat{\alpha}}_1^{elec,p}$, ${\hat{\alpha}}_2^{elec,p}$ denote the estimate of coefficients of the auxiliary model. $\left({\hat{\sigma}}^{gas,p}\right)^2$ as the function of floor area can also be obtained in the same way.
The explained approach can be extended to estimate the heteroskedasticity structure of covariance between error terms of two different regression models as a function of the explanatory variables [27]. For the two regression models corresponding to electricity uses in $p$th and $q$th months, the auxiliary regression model can be set up as in Equations 8 and 9.
where ${\hat{\sigma}}{\left(p,p\right)}^{e,e}=\left({\hat{\sigma}}^{elec,p}\right)^2$ and $e$ in the superscript denotes electricity. ${\hat{\sigma}}{\left(p,q\right)}^{g,g}$ and ${\hat{\sigma}}_{\left(p,q\right)}^{e,g}$ can also be obtained in the same way (where $g$ in the superscript denotes gas).
However, estimate of covariance by Equation 9 may produce unrealistic value of covariance, such as negative variance and negative correlation between error terms of regression models corresponding to electricity use in January and February. For the subset of office buildings with floor area under 3,000 m2 using gas, the variance of $\epsilon_i^{elec,1}$ and covariance between $\epsilon_i^{elec,1}$ and $\epsilon_i^{elec,2}$ have been estimated as ${\hat{\sigma}}{\left(1,1\right)}^{e,e}=-39278300+75969x_i^{area}-5.99\left(x_i^{area}\right)^2$ and ${\hat{\sigma}}{\left(1,2\right)}^{e,e}=-35607600+70291x_i^{area}-6.37\left(x_i^{area}\right)^2$, respectively. Both estimates become negative if $x_i^{area}$ is lower than about 500 m2, which are practically positive but incorrectly estimated.
To prevent unrealistic estimation of covariance by change of sign, Equations 8 and 9 have been modified to contain only the second order term of floor area in the right side, as in Equations 10 and 11.
The estimate of covariance matrix, constructed by aggregation of all estimates of covariance computed by Equation 11, is generally not positive semidefinite. However, a covariance matrix must be positive semidefinite by its properties. Thus, a positive semidefinite matrix nearest to the estimate of covariance matrix should be computed to be used as the covariance of the joint probability model of monthly energy uses.
The nearest positive semidefinite matrix can be obtained by eigen-decomposition. Denote the estimate of covariance matrix obtained by Equation 11 as $\hat{{\scriptstyle\sum}}$. $\hat{{\scriptstyle\sum}}$ is generally not positive semidefinite, but it is real-valued and symmetric. Thus, it can be decomposed as $\hat{{\scriptstyle\sum}}=VDV^T$ where $V$ is a square matrix containing eigenvectors of $\hat{{\scriptstyle\sum}}$ as its columns, and $D$ is a diagonal matrix containing eigenvalues of $\hat{{\scriptstyle\sum}}$ as its diagonal elements. Defining a new matrix $D_+$ which is obtained by replacing negative elements of $D$ with zeros, the nearest positive semidefinite matrix ${\hat{{\scriptstyle\sum}}}_+$ can be computed as ${\hat{{\scriptstyle\sum}}}_+=VD_+V^T$. Then, ${\hat{{\scriptstyle\sum}}}_+$ is used as the covariance matrix of the joint probability model for monthly energy uses. Table 8 shows the values of elements in ${\hat{{\scriptstyle\sum}}}_+$ for unit floor area, for the subset of office buildings with floor area under 3,000 m2 using gas. The covariance matrix of the vector of monthly energy uses for a certain office building under 3,000 m2 using gas can be obtained by multiplication of square of its floor area with the elements in Table 7. For other subsets, different estimates of covariance matrix would be obtained.
Table 8. Estimates of coefficients of squared floor area for estimation of covariance as a function of floor area ((a): ${\hat{\alpha}}{\left(p,q\right)+}^{e,e}$, (b): ${\hat{\alpha}}{\left(p,q\right)+}^{g,g}$, (c): ${\hat{\alpha}}_{\left(p,q\right)+}^{e,g})$. + in the subscript emphasizes that the resulting covariance matrix is positive semidefinite.
Figure 5 shows that the estimates of covariance from ${\hat{{\scriptstyle\sum}}}_+$ represents the heteroskedasticity of the data well. Adding a subscript $+$ which emphasizes that the covariance matrix is positive semidefinite, the modified bands $x_i^T{\hat{\beta}}^{elec,1}\pm2.58{\hat{\alpha}}_{\left(1,1\right)+}^{e,e}\ \left(x_i^{area}\right)^2$ and $x_i^T{\hat{\beta}}^{gas,1}\pm2.58{\hat{\alpha}}_{\left(1,1\right)+}^{g,g}\ \left(x_i^{area}\right)^2$ (depicted as grey areas) capture the increasing variance well while they do not contain regions where no data point is located.
Figure 5. Residual plots for the linear regression model corresponding to energy uses in January, for the subset of office buildings with floor area under 3,000 m2 using gas (Left: electricity, Right: gas). The grey areas denote the modified band of $x_i^T{\hat{\beta}}^{elec,1}\pm2.58{\hat{\alpha}}{\left(1,1\right)}^{e,e}\ \left(x_i^{area}\right)^2$ and $x_i^T{\hat{\beta}}^{gas,1}\pm2.58{\hat{\alpha}}{\left(1,1\right)}^{g,g}\ \left(x_i^{area}\right)^2$, which capture heteroskedasticity of data well.
4. Joint probability model
4.1. Multivariate normal distribution of monthly energy usage
A multivariate normal distribution for monthly electricity and gas uses for a year can be defined based on the mean vector and covariance matrix of monthly energy uses in a building obtained by the procedure presented in Section 3, conditional on the features of the building (floor area, number of stories, and approval year of the building), as Equation 12.
where MVN is the abbreviation of multivariate normal. The covariance matrix of the distribution contains $\left(x_i^{area}\right)^2$, meaning reflection of heteroskedasticity. There are two advantages of multivariate normal distribution – i) it is one of the simplest multivariate distributions for model construction, interpretation, maintenance, and sampling; and ii) it provides reasonable fit to near-symmetric data with high variance, which is the case of this study (Figure 6).
Figure 6. Empirical distribution of residuals from the linear regression model corresponding to electricity use in January, for the subset of office buildings with floor area under 3,000 m2 using gas. The distribution is bell-shaped and the mode of the distribution is close to zero, which means that approximate normal distribution is applicable to this data.
Figure 7 shows some samples of monthly energy use for one year drawn from the multivariate normal distribution fitted for the subset of office buildings using gas, conditional on floor area 1,500 m2, seven stories, approved for use in 2000, which show reasonable seasonal patterns of energy use. The key to success in reflection of seasonality in monthly energy use is consideration of covariance between energy uses in different months or different energy types, which was not considered in previous studies. If the covariance is ignored, then samples drawn from the distribution which assumes independency of energy uses in different months or different energy types will show unrealistic seasonal patterns. Figure 8 shows some samples drawn from a different distribution with modified covariance matrix where its off-diagonal elements were replaced with zero. The samples show unrealistic seasonal patterns. Meanwhile, the magnitudes of energy use of the samples in Figure 7 are different to each other due to inevitable high variance nature of the data.
Figure 7. Four samples of monthly energy use for one year drawn from the multivariate normal distribution fitted for the subset of office buildings using gas, conditional on floor area 1,500 m2, seven stories, approved for use in 2000. The samples show realistic seasonal patterns.Figure 8. Two samples of monthly energy use for one year drawn from an alternative multivariate normal distribution with modified covariance matrix where its off-diagonal elements were replaced with zero. The samples show volatile and unrealistic seasonal patterns.
To obtain reasonable samples, a post-processing is required because a number of samples may show unrealistic seasonal patterns. Denote the monthly electricity use for a year in a sample drawn from the multivariate normal distribution as $y_0^{elec}$. Then, dividing it into its absolute value norm as ${\widetilde{y}}_0^{elec}=y_0^{elec}/\left|y_0^{elec}\right|_1$, the quantity $\left({\widetilde{y}}_0^{elec}\right)^T\left(\left({\widetilde{Y}}^{elec}\right)^T{\widetilde{Y}}^{elec}\right)^{-1}{\widetilde{y}}_0^{elec}$ can be computed (as similarly done in Section 2.3.2), where ${\widetilde{Y}}^{elec}$ multiplied with ${\widetilde{y}}_0^{elec}$ is the matrix composed of data preserved after pre-processing in Section 2.3.2. Samples with the quantity over a threshold ($2k/N$ in this study, but it can be adjusted by the user) are deleted. In a numerical experiment for the case of office building using gas with floor area 1,500 m2 of floor area and seven stories, about 61% of initially drawn samples are preserved after the post-processing. On the contrary, when the post-processing is applied to the samples from the different distribution with ignorance of covariance between error terms for different months, none of the samples are preserved.
4.2. Application to data correction
In practice, some values in the record of monthly energy use in a building may be missing or incorrect. Figure 9 shows screenshots of some rows in the database of monthly energy use, which have missing or abnormally low values. If there is a method of filling the missing values or replacing unusual values with reasonable alternative values, it would help enhance data quality of the energy use record. However, models in previous studies with ignorance of covariance or simplified time-series models cannot be used for such task of data correction.
Figure 9. Screenshots of some rows in the dataset of monthly energy use, containing missing or abnormally low values.
The joint probability model introduced in Section 4.1 can be used for data correction, based on the conditional multivariate normal distribution where the energy use in month with correct values in the record are assumed to be fixed. For a random vector variable $z=\left[z_1^T,\ z_2^T\right]^T$ following multivariate normal distribution where $z_2$ has been fixed to be $a$, the conditional multivariate normal distribution of $z_1$ can be expressed as Equation 13.
If $z$ is monthly electricity use for a year in a target building where electricity use values for some months $z_2$ are correct to be a but the values for the other months $z_1$ are missing or incorrect, the parameters $\mu_1$, $\mu_2$, ${\scriptstyle\sum}_{11}$, ${\scriptstyle\sum}_{12}$, ${\scriptstyle\sum}_{21}$, ${\scriptstyle\sum}_{22}$ become the electricity part of the mean and covariance the joint probability model in Equation 12. The mean of the conditional multivariate normal distribution $\mu_1+{\scriptstyle\sum}_{12}{\scriptstyle\sum}_{22}^{-1}\left(a-\mu_2\right)$ can be used as the alternative values for filling the missing values or replacing the incorrect values.
Figure 10. Actual monthly energy use in an exemplary building (connected curve) and estimation of the energy use by the conditional multivariate normal distribution (circles and squares), where the estimation for each group of different marker types has been computed based on assumption of missing values in the corresponding months (Left: electricity, Right: gas).
Figure 10 shows that the mean of the conditional multivariate normal distribution in Equation 13 produces reasonable alternative values. The curve denotes the actual recorded monthly energy use in the exemplary building with known floor area, number of stories and approval year. The circles denote the estimation of energy uses equal to the mean of the conditional multivariate normal distribution, assumed that the energy use record of the months corresponding to the circles (February, July, and October) are missing while record of the other months are available. The squares have the similar meaning as circles (assumed missing values in October, November, and December). The case of squares can be viewed as prediction of monthly energy use since the values of last three months are assumed to be missing and estimated given the energy use of preceding months. For electricity, the estimated values are quite close to the actual record. For gas, although the estimated values are a little deviated from the actual record due to the high variance of gas data, the new data generated by replacing the estimated values shows realistic seasonal pattern.
5. Summary
This study provides a statistical method to model the ‘joint’ probability distribution of ‘monthly’ electricity and gas uses for a year in individual urban buildings, conditional on the feature of the buildings. The process has been summarized as below:
i) Pre-process the database of monthly energy use and building features. Data points with missing values, or abnormal seasonal pattern of monthly energy use, or abnormal magnitude of energy use have been deleted. Points with abnormal seasonal pattern have been identified by a method which quantifies remoteness of each point from the cluster of the points applied to a transformed dataset. Points with abnormal magnitude of energy use have been identified by computation of Cook’s distance.
ii) For each subset of database (divided with respect to building use, floor area interval, use of gas), fit individual linear regression models. The response variable of each regression model is electricity or gas use in each month of buildings. In this study, the selected explanatory variables are floor area, number of stories, and approval year for use of buildings. Obtain the estimates of coefficients and residuals of the regression models.
iii) Establish auxiliary regression models to estimate the covariance of the errors as an increasing function of increasing floor area (in other words, estimate the structure of heteroskedasticity in the data). The response variable is multiplication of two residuals, each from regression models corresponding to the same or different months or energy types. The only explanatory variable is the square of floor area (no intercept). Transform the obtained estimate of covariance matrix into its nearest positive semidefinite matrix.
iv) Define a multivariate normal distribution conditional on the features of a building, where its mean vector is computed based on the estimates of coefficients obtained in ii) and its covariance matrix is computed based on the estimates of covariance matrix obtained in iii).
The joint probability model can be used to generate samples of monthly energy uses for a year in a target building, with realistic seasonal pattern and magnitude. Also, the joint probability model can be used to fill missing values or replace incorrect values of monthly energy use in a building with reasonable estimations, given that some correct values of monthly energy use are recorded in that building. The key to success of the provided model is the consideration of covariance between monthly energy uses, which exists even after controlling the effects of building size, height, and age.
References
[1] IEA (2022), Buildings, IEA, Paris https://www.iea.org/reports/buildings, License: CC BY 4.0
[2] Li, Z., Han, Y., & Xu, P. (2014). Methods for benchmarking building energy consumption against its past or intended performance: An overview. Applied Energy, 124, 325-334.
[3] Seyedzadeh, S., Rahimian, F. P., Glesk, I., & Roper, M. (2018). Machine learning for estimation of building energy consumption and performance: a review. Visualization in Engineering, 6(1), 1-20.
[4] Ciulla, G., & D'Amico, A. (2019). Building energy performance forecasting: A multiple linear regression approach. Applied Energy, 253, 113500.
[5] Turiel, I., Craig, P., Levine, M., McMahon, J., McCollister, G., Hesterberg, B., & Robinson, M. (1987). Estimation of energy intensity by end-use for commercial buildings. Energy, 12(6), 435-446.
[6] Pérez-Lombard, L., Ortiz, J., & Pout, C. (2008). A review on buildings energy consumption information. Energy and buildings, 40(3), 394-398.
[7] Zhong, X., Hu, M., Deetman, S., Rodrigues, J. F., Lin, H. X., Tukker, A., & Behrens, P. (2021). The evolution and future perspectives of energy intensity in the global building sector 1971–2060. Journal of Cleaner Production, 305, 127098.
[8] Olofsson, T., Andersson, S., & Sjögren, J. U. (2009). Building energy parameter investigations based on multivariate analysis. Energy and Buildings, 41(1), 71-80.
[9] Howard, B., Parshall, L., Thompson, J., Hammer, S., Dickinson, J., & Modi, V. (2012). Spatial distribution of urban building energy consumption by end use. Energy and Buildings, 45, 141-151.
[10] Andrews, C. J., & Krogmann, U. (2009). Technology diffusion and energy intensity in US commercial buildings. Energy Policy, 37(2), 541-553.
[11] Hsu, D. (2015). Identifying key variables and interactions in statistical models of building energy consumption using regularization. Energy, 83, 144-155.
[12] Apadula, F., Bassini, A., Elli, A., & Scapin, S. (2012). Relationships between meteorological variables and monthly electricity demand. Applied Energy, 98, 346-356.
[13] Song, J., & Song, S. J. (2020). A framework for analyzing city-wide impact of building-integrated renewable energy. Applied Energy, 276, 115489.
[14] Smith, A., Fumo, N., Luck, R., & Mago, P. J. (2011). Robustness of a methodology for estimating hourly energy consumption of buildings using monthly utility bills. Energy and Buildings, 43(4), 779-786.
[15] Pagliarini, G., & Rainieri, S. (2012). Restoration of the building hourly space heating and cooling loads from the monthly energy consumption. Energy and buildings, 49, 348-355.
[16] Lamagna, M., Nastasi, B., Groppi, D., Nezhad, M. M., & Garcia, D. A. (2020, December). Hourly energy profile determination technique from monthly energy bills. In Building Simulation (Vol. 13, No. 6, pp. 1235-1248). Tsinghua University Press.
[17] Catalina, T., Virgone, J., & Blanco, E. (2008). Development and validation of regression models to predict monthly heating demand for residential buildings. Energy and buildings, 40(10), 1825-1832.
[18] Kim, MK., Kim, BS., & Kim, JA. (2014). Development of a standard model for energy consumption in residential and commercial buildings in Seoul. City of Seoul, ISBN: 9791156212942 93530.
[19] Xu, J., Kang, X., Chen, Z., Yan, D., Guo, S., Jin, Y., ... & Jia, R. (2021, February). Clustering-based probability distribution model for monthly residential building electricity consumption analysis. In Building Simulation (Vol. 14, No. 1, pp. 149-164). Tsinghua University Press.
[20] Hastie, T., Tibshirani, R., Friedman, J. H., & Friedman, J. H. (2009). The elements of statistical learning: data mining, inference, and prediction (Vol. 2, pp. 1-758). New York: springer.
[21] Araji, M. T. (2019, August). Surface-to-volume ratio: How building geometry impacts solar energy production and heat gain through envelopes. In IOP Conference Series: Earth and Environmental Science (Vol. 323, No. 1, p. 012034). IOP Publishing.
[22] Chow, G. C. (1960). Tests of equality between sets of coefficients in two linear regressions. Econometrica:Journal of the Econometric Society, 591-605.
[23] Hoaglin, D. C., & Welsch, R. E. (1978). The hat matrix in regression and ANOVA. The American Statistician, 32(1), 17-22.
[24] Cook, R. D. (1977). Detection of influential observation in linear regression. Technometrics, 19(1), 15-18.
[25] Davidson, R., & MacKinnon, J. G. (1993). Estimation and inference in econometrics (Vol. 63). New York:Oxford.
[26] Amemiya, T., & AMEMIYA, T. A. (1985). Advanced econometrics. Harvard university press.
[27] Mandy, D. M., & Martins-Filho, C. (1993). Seemingly unrelated regressions under additive heteroscedasticity: Theory and share equation applications. Journal of Econometrics, 58(3), 315-346.
Is Bubble in Auction Market Really Bubble? Bubble Index in Real Estate Auction Market
Published
Hyeyoung Park*
* Swiss Institute of Artificial Intelligence, Chaltenbodenstrasse 26, 8834 Schindellegi, Schwyz, Switzerland
Abstract
In this study, we address the phenomenon of financial bubbles, where asset or commodity prices deviate significantly from their intrinsic value or market consensus. Typically, bubbles go unnoticed until they burst, causing abrupt price declines. Given the global interconnectedness of markets, such bubbles can have profound economic repercussions, emphasizing the importance of proactive detection and management. Our approach focuses on predicting bubbles in auction markets, driven by crowd psychology or the 'herd effect.' We posit that these bubbles manifest as a 'winner's curse' in auctions, and that if investors flock to the auction, the difference between the first and second place prices will be frequently large. While prior research in real estate and auction markets has relied on hedonic pricing models, our study distinguishes itself by employing mathematical statistical modeling alongside a hedonic pricing framework. Specifically, we employ logistic regression, with corrected winning bid rates as the dependent variable and various auction-related factors as independent variables, excluding intrinsic property value. We also employ a Chow-test to assess structural changes within the market over time, examining whether the Bubble Index, a novel metric indicating the intensity of auction competition, has varying effects on distinct market subgroups. Moreover, unlike previous studies, we statistically validate the existence of bubbles in auction markets through the development of a Bubble Index. Our results reveal that the explanatory power of this index significantly increases post-structural shock, with a maximum impact of 5.65% on the winning bid rate.
Bubbles in financial assets or commodities, characterized by prices exceeding intrinsic value, have historically posed risks to markets and economies[8]. Often, these bubbles go unrecognized until they burst, resulting in significant investor losses. This phenomenon, fueled by "herd psychology" and amplified by modern communication channels like social media, necessitates proactive detection and management.
This study investigates potential market overheating in the Gangnam-gu apartment real estate auction market from 2014 to 2022, focusing on identifying bubbles and overheating. Unlike previous studies predicting the winning rate, we study the existence and overheating of bubbles based on the idea that price competition in the auction market will intensify when a bubble occurs due to the nature of auction competition. We introduce a "bubble index" to statistically validate bubble existence and assess its differential impact on subgroups when market structural shocks occur, which is an index of when competition in an auction becomes overheated and the difference between the first and second place prices becomes large. This study involves checking whether the explanatory power of the bubble index after a structural shock is significantly higher than before that point.
1.2 Features of the Korean Real Estate Auction System and Bubbles
Korea's real estate auction system, a sealed-bid process with participants' prices undisclosed, promotes individual independence[1]. In addition, it employs first-price auctions, where the highest bid determines the winning price, influenced by price competitiveness and return on investment.
In overheated markets, increased liquidity and rising prices may elevate expected returns, potentially leading to irrational market conditions. External shocks can disrupt individual independence, fostering a Winner's Curse scenario[2][3], where the winning bidder pays more than the objective value, characterizing an overheated market. A noteworthy behavior is a frequent large gap between the first and second-place prices, akin to bubble dynamics, reflecting intense competition.
In general, it is rational for bidders to place bids that are lower than the asking price and higher than their competitors, and it is unusual for bidders to place bids that are overwhelmingly larger than their competitors. Therefore, if a large gap between the first and second place prices is a frequent occurrence in an auction market, we can assume that there are many confident investors. This is similar to the behavior of a bubble, where competition drives prices up due to aggressive investment by new investors entering the market.
This "bubble index" uses the first-to-second-place price difference and integrates it into a regression model as an independent variable. Additionally, we account for the time difference between appraisal and winning bids by calibrating appraised prices to market values at the auction time.
2. Review of Prior Research
Previous studies in real estate auctions have predominantly focused on factors influencing the winning bid price, utilizing either the hedonic pricing model[5] or time series data analysis.
Lee, H.K, Bang, S.H and Lee, Y.M (2009)[9]: Employed a hedonic pricing model to estimate winning bid prices for apartment auctions. Noted that during rising apartment prices, the time-calibrated winning bid rate exceeded the original rate, with the opposite occurring during declines.
Lee, J.W and Bang, D.W (2015)[10]: Analyzed housing characteristics, auction specifics, and macroeconomic variables' impact on the winning bid rate via a hedonic model. Significant influencers included the number of bidders, the number of failed bids, and market interest rates, with varying effects in upswing and downswing periods.
Jeon, H.J (2013)[4]: Utilized a VECM model to examine the time series pre and post-global financial crisis. Observed the disappearance of house price appreciation expectations post-crisis, leading to an increase in the number of items in the auction market and a decrease in the winning bid rate.
Despite these insights, the use of the hedonic pricing model carries limitations:
Limitation 1: Multicollinearity Concerns Due to indiscriminate variable addition, multicollinearity issues may arise. The model's explanatory power diminishes, leading to unreliable results when excessive variables are included without due consideration.
Limitation 2: Intrinsic Value Ambiguity Determining the intrinsic value of a property is challenging due to numerous influencing factors such as school zones, job prospects, infrastructure, and urban planning.
Limitation 3: Assuming a homogeneous market over the entire period Furthermore, prior studies often categorized periods as rising, falling, or freezing without considering structural market changes.
Since the mid-2010s, the hedonic model has seen limited use in predicting auction prices due to these limitations.
This study seeks to address these limitations as follows:
Constructing a model with judiciously selected variables and appropriate controls.
Mitigating intrinsic value complexity by using the winning bid rate, not price, as the dependent variable and employing a logit model.
Employing a Chow-test to segregate datasets, uniquely focusing on bubble phenomena stemming from irrational investment sentiment in overheated markets to reveal structural shifts.
Table 1: Explanatory Variables Used in Prior Research
3. Research Area Selection and Data Pre-processing
3.1 Comparison of Auction Cases in 25 Seoul Wards and Area Selection
To ensure an adequate dataset, we examined appraisal prices and winning bids distributions in five of Seoul's 25 wards from January 2014 to December 2022: Yangcheon-gu, Gangseo-gu, Songpa-gu, Gangnam-gu, and Nowon-gu, known for high apartment transaction volumes(Figure 1). Excluding urban living houses (one-room units with a floor area of 85 square meters or less), deemed dissimilar to the apartment market, left us with Nowon-gu and Gangnam-gu as the primary areas of focus due to their significant auction event numbers. Nowon-gu and Gangnam-gu had the highest number of auction events, but there were significant differences in the price distribution(Figure 2). After assessing auction event data and the bubble index, we opted to focus our analysis on Gangnam-gu, where no data gaps exist.
Figure 1: Number of auction cases for each ward in Seoul from 2014 to 2022.Table 2: Number of auction events with 2 or more bidders in Gangnam-gu and Nowon-gu.
3.2 Bubble Index using the Price Difference
To identify potential bubbles, we considered the frequency of large price differences between first and second place bids in auction markets. Our goal was to create a bubble index based on these differences. We aggregated price differences from auctions with more than two bidders (excluding solo bids) and calculated quarterly averages to minimize missing data.
To capture changes effectively, we employed the geometric mean of quarterly price differences, instead of the arithmetic mean, due to the baseline. This method revealed notable increases compared to the baseline year (2014). Notably, Nowon-gu had no auction events in Q4 2021 and Q1 2022, leading to missing data. We opted not to use the difference between first and third place bids due to more frequent missing values and data collection challenges.
3.3 Time Correction of Winning Bid Rate
In the auction system, a time gap exists between building appraisal and the actual winning bid \(\frac{B_i}{A_i}\). This discrepancy affects the winning bid rate, which should reflect surcharges or discounts relative to market prices accurately[9]. To rectify this, we corrected the appraised price using the KB market price. The resulting corrected winning bid rate \(\frac{B_i}{A'_i}\), calculated by dividing the winning bid by the adjusted appraised price, serves as our dependent variable.
\[ A'_i = \frac{A_i \cdot S_p}{S_{p-t}} \]
Figure 2: Box and whisker plot of appraisal prices and winning bids of five wards.Figure 3: Number of auction events with 2 or more bidders per quarterFigure 4: Average of the price difference by quarterFigure 5: Geometric mean of quarterly price differenceFigure 6: Distribution of winning bid rate and corrected winning bid rate
\(A'_i\) represents the adjusted appraised value, where \(A_i\) is the original appraised value, \(S_p\) is the KB market price at the time of winning the bid, and \(S_{p-t}\) represents the KB market price at the time of appraisal.
When comparing the distribution of winning bid rate and corrected winning bid rate(Figure 6), it's evident that the average corrected winning price is lower both in Gangnam-gu (from 96.8% to 93.0%) and Nowon-gu (from 95.6% to 92.3%). This observation underscores the significant impact of the time gap between appraisal and auction. Typically, during this time difference, market prices, reflecting buying and selling dynamics, tend to rise.
Analyzing the average winning bid rate and the corrected winning bid rate by quarter reveals an interesting trend(Figure 7). In Gangnam-gu, the gap between these rates began widening after a specific point (Q1 2016), indicating increased price fluctuations in the buying and selling market. Since Q1 2018, this gap has continued to grow. The fact that the corrected winning bid rate is consistently lower than the winning bid rate in recent years suggests that price increases are occurring in the buyer's market, aligning with the decrease in the number of auctions as the buyer's market becomes more active.
In Nowon-gu, the winning price ratio slightly exceeds the corrected winning price ratio for all time periods, implying that market prices and winning prices in Nowon-gu are relatively similar, despite the steady increase in market prices.
3.4 Adjustment of Bubble Index Considering Time Series Analysis
To identify structural changes attributed to a bubble, which signifies an overheated market, the data must be presented in a continuous time series format. A Chow-test serves as a valuable tool for comparing coefficients from two linear regressions on before-and-after datasets in time series data, detecting structural shocks or changes. Essentially, the Chow-test assesses if the impact of the independent variable (the bubble index) on the dependent variable varies before and after a specific point. Therefore, we transform the quarterly bubble index into time series data by adjusting it to a geometric mean of \(k\) consecutive observations(Figure 8).
Figure 7: Comparison of average winning bid rate and corrected winning bid rate in quarter
In this equation, \(j\) represents the index for the winning bid order (e.g., 1, 2, ...), \(k\) represents the size of the dataset, \(P_i^t\) represents the geometric mean of price differences at time \(t\) over a dataset of size \(k\), \(P^0\) represents the geometric mean of price differences at a reference time point over a dataset of size \(k\), and \(D_i\) represents the difference between the winning bid price (1st place) and the second-place bid price for a specific event.
4. Analytical Model Setup
Historically, many studies predicting real estate prices have employed the hedonic pricing model, which incorporates numerous property-specific variables. However, this approach has faced limitations such as multicollinearity, intrinsic value ambiguity, and market homogeneity assumptions.
Our study seeks to overcome these limitations by utilizing a hedonic pricing model, specifically regression analysis, coupled with mathematical statistical modeling to detect real estate bubbles. In this model, logistic regression excludes intrinsic property value as the dependent variable, using the corrected winning bid rate instead. Independent variables include the number of auctions, number of bidders, the difference between the first and second prices (bubble index), and M2 currency volume.
We employ the Chow-test to segregate data sets, assuming structural market changes over the entire period. In the event of a structural market shock, like a bubble, we examine whether the independent variable (the bubble index) exhibits different effects on subgroups.
4.1 Equation Construction
The traditional hedonic model, explaining prices as the sum of intrinsic values, may not be suitable for bubble detection, as bubbles often occur when intrinsic values are challenging to measure. To eliminate intrinsic value, we utilize the winning bid rate in a regression on logarithmic dependent and independent variables. The model takes the form:
Here, \(A_i\) represents the appraised value, reflecting market prices, including intrinsic property value. \(B_i\) is the winning bid, encompassing intrinsic value, bidder risk, and bubble-induced competition. Taking the natural logarithm of both prices eliminates intrinsic property value from the equation. The error term \(v_i\) is minimal due to the high sales and transaction volume for apartments like the ones analyzed in this study. \(X_in\) represents independent variables explaining the winning bid rate, such as risk factors and auction event bubbles.
Due to the time gap between appraisal and winning bids, we use a time-corrected appraised value defined in Part 3-4 as the equation:
Where, \(\frac{B_i}{{A'}_i}\) is the time-corrected winning bid rate, \(\alpha_i\) is a constant resulting from time correction with error term and \(X_{in}\) represents \(N\) independent variables of specific auction event \(i\).
4.2 Variable Characteristics
The variables employed in prior studies can be broadly categorized into macroeconomic variables, housing characteristics, and auction characteristics. Notably, variables pertaining to the intrinsic value of real estate have been excluded through the logit model outlined in Equation 4-1. In this study, we have opted to utilize the following independent variables: the bubble index, number of bidders, number of failed auctions, and M2 currency volume.
The "Index 5" variable, which we refer to as the bubble index, was defined in Part 3-4 following a meticulous selection process that considered time series analysis.
While the bubble index scrutinizes bubbles within the auction market, the number of bidders serves as a key indicator to gauge the extent of competitive overheating during individual events. This variable has been widely employed in several studies and is limited to events featuring two or more bidders[6][7].
Figure 9: Distribution of Variables
Previous studies have delved into risk factors associated with auction events, often segmenting them into various variables. Among these, the number of unsuccessful bids has emerged as one of the most influential variables, serving as an instrumental indicator. Regarding the number of bids, we apply a logit model and categorize the data as follows: 1 for new events with no failures, 2 for events with one failure, 3 for events with two failures, and 4 for events featuring three or more failed bids.
Aligned with the notion that bubbles tend to emerge when accurate price estimation becomes challenging, we incorporate the M2 currency volume as an indicator. This variable takes into account market liquidity and is applied using the initial analysis period of January 2014 as a baseline (set to 1).
The characteristics of the variables utilized in the hedonic model of this study are summarized in the table below(Table 3).
Table 3: Descriptive Statistics of Variables
4.3 Chow-Test for Structural Changes
The Chow-test is a statistical tool for detecting structural breaks in time series data by comparing coefficients from two linear regressions on before-and-after data sets. In our analysis of Gangnam-gu auction data, we employed a calibrated regression model of the winning bid rate, including the bubble index, number of bidders, and number of winning bids.
The Chow-test results revealed a structural break at point 321 (Q1 2018), indicating a significant change in the regression coefficients(Figure 10). A subsequent analysis, adding M2 currency volume as an independent variable, identified a break at point 226 (Q2 2016).
5. Analysis Results
5.1 Regression Model
The Ordinary Least Squares (OLS) analysis of the calibrated winning bid rate regression model, utilizing three variables: the bubble index, number of bidders, and number of wins, is presented below. The dataset preceding the break point is referred to as "Subset 1," while the dataset succeeding the break point is termed "Subset 2." We also provide the effective coefficients and standard deviation results for the entire dataset(Table 4).
The relatively low R-squared value of the model and the less significant t-test statistics associated with the bubble index can be attributed to the potential presence of omitted variables. To address this concern, we introduced M2 currency volume as an additional variable and examined the results of the regression model equation with four variables.
As a result, the R-squared value demonstrated improvement compared to the three-variable regression model, and notably, the estimated coefficient of the bubble index achieved statistical significance(Table 5). Additionally, the effective coefficients for the number of auctions and number of bidders variables showed increases, revealing a negative correlation between the number of auctions and M2, and a positive correlation between the number of bidders and M2. This suggests that over time, an increase in M2 corresponds to rising real estate prices, a phenomenon reflected in the model through the differential between the winning bid rate and the corrected winning bid rate.
The residual plot further verifies the resolution of the omitted variable issue, taking the form of a random cloud.
We observed that the influence of the bubble index intensified just before break point 226 and reached its maximum impact at break point 306 (Q4 2017). At this time, a 1-point increase in the Bubble Index raised the corrected winning bid rate by 5.12% in average.
5.2 Bubble Index
The Bubble Index, reflecting the intensity of price differences between the first and second bidders, operates during periods of real estate price appreciation. It provides insights into the cycle and size of real estate bubbles, acting as an indicator of investors' expectations.
5.3 Other Variables
The effect of the number of unsuccessful bids on the winning bid rate diminished significantly after point 306, indicating that winning bids had less impact on the winning rate as the bubble deepened.
The increase in the number of bidders positively correlated with the Bubble Index, aligning with the "winner's curse" phenomenon. M2 currency volume did not significantly impact the winning bid rate but served as a control variable.
5.4 Bubble Index Over Time
The Bubble Index analysis for data with more than two bidders revealed fluctuations in the degree of overheating in auction markets. Notably, overheating increased over time, with the ratio between the first and second bidders' prices reaching peak values in recent years.
The data set was divided using the Chow test, and the analysis indicated that the Bubble Index operated differently in the sub-data sets before and after the break point (Q2 2016).
Figure 10: Chow-test statistics according to break pointsTable 4: Regression with 3 variablesTable 5: Regression with 4 variablesFigure 11: Statistic values according to break pointsFigure 12: Statistic values according to break points
5.5 Implications
The Bubble Index, derived from the price difference between the first and second place bids, effectively explains auction market overheating. Its sustained high values suggest ongoing overheating, with the average Bubble Index remaining elevated since Q3 2020. This index can serve as an early warning indicator for investors before the bubble deepens.
In conclusion, our analysis indicates that the Bubble Index reflects market expectations and effectively detects real estate market overheating. However, it's important to note that the index may become distorted at the peak of a bubble when fewer auction events occur.
6. Conclusion
In this comprehensive study, we meticulously examined the presence and magnitude of bubbles within the auction market through a systematic approach. To begin, we devised a bubble index, tailored to instances featuring more than two bidders, which served as an essential metric for gauging the escalation in price disparities between the top two bidders over time.
Subsequently, employing the Chow test—an analytical technique comparing the regression coefficients of two distinct phases in time series data—we partitioned the dataset. This division unveiled varying behaviors in the effective coefficient and t-statistic values associated with our bubble index across these distinct segments.
Notably, the segmentation pinpointed a crucial turning point in the second quarter of 2016, where the t-test value for the bubble index transformed from being inconclusive to significant. Furthermore, within the later dataset, the bubble index exhibited a substantial effective coefficient of 0.055, indicating a noteworthy 5.65% influence on the winning bid rate. Meanwhile, the t-test outcomes for the other variables remained consistently valid throughout both datasets.
This investigation yielded a multifaceted picture: before the bifurcation point, the model displayed a coefficient of determination (R-squared) of 77.6%, along with an Adjusted R-squared of 77.4%, signifying its robust explanatory power. Following the division, the model maintained considerable explanatory capacity, with an R-squared of 76.8% and an Adjusted R-squared of 76.2%. Moreover, it became evident that competition intensified, as witnessed by the average corrected winning bid rate increasing from 91% to 96% post-bifurcation.
Our utilization of the Bubble Index proved invaluable. It highlighted not only transient spikes but also persistent hotspots as key indicators of market overheating. Since the third quarter of 2020, the average Bubble Index for each auction order has consistently held at 6.04, underscoring a prolonged state of overheating in the auction market.
In conclusion, this study underscores the utility of the Bubble Index, founded on the price disparity between first and second place bids, as an effective metric for elucidating overheating tendencies in the auction market—an insight reflective of investor sentiment. Nevertheless, it's important to acknowledge that the Bubble Index may become distorted at the peak of a bubble due to dwindling auction events. Despite this limitation, it holds promise as a preventive tool to alert investors before the escalation of a market bubble.
References
[1] Allen, and Marcus, T. Discounts in real estate auction prices: Evidence from south florida. Journal of Real Estate Research 25, 3 (2001), 38—-43.
[2] Bazerman, Max, H., and William, F., S. I won the auction but don’t want the prize. Journal of Conflict Resolution 27, 4 (1983), 618––634.
[3] Capen, Edward, C., Robert, V., C., and William, M., C. Competitive bidding in high-risk situations. Journal of Petroleum Technology 23 (1971), 641—-653.
[4] Jeon, H. An empirical study on the correlation between the housing sales market and auction market -focused on before and after the global financial crisis. Korea Real Estate Review 23, 2 (2013), 117–132.
[5] Jin, N., Lee, Y., and Min, T. Is the selling price discounted at the real estate auction market? Housing Studies Review 18, 3 (2010), 93–117.
[6] Kagel, John, H., and Dan, L. The winner’s curse and public information in common value auctions. The American Economic Review 76, 5 (1986), 894—-920.
[7] Kagel, John, H., and Dan, L. Common value auctions and the winner’s curse. NJ: Princeton University Press.
[8] Karl, E., C., and Robert, J., S. Is there a bubble in the housing market? In Brookings Papers on Economic Activity (2003), vol. 2, The Johns Hopkins University Press, pp. 299–342.
[9] Lee, H., Bang, S., and Lee, Y. True auction price ratio for condominium: The case of gangnam area, seoul, korea. Housing Studies Review 17, 4 (2009), 233–258.
[10] Lee, J., and Bang, D. Factors influencing auction price ratio: Auction characteristics, macroeconomic variables. Korea Real Estate Review 25, 2 (2015), 71–84.